开篇:奖励模型挺重要,但不好搞啊!
为啥要聊奖励模型?
现在大语言模型(LLM)是越来越火,能力也越来越强。但光能打还不行,还得听话,得知道啥是对的、啥是好的,不能瞎来。这就是所谓的“对齐”(Alignment)。要让 LLM 听话,强化学习(RL)就成了关键技术。在这个过程中,有个角色特别重要,那就是奖励模型 (Reward Model, RM) 。你可以把它想象成一个裁判,专门负责给 LLM 生成的内容打分,告诉 RL 哪个好、哪个不好,这样 LLM 才能学好。
裁判不好当:挑战重重
虽然 RM 这么重要,但想训练出一个完美的 RM 裁判可不容易,特别是我们希望它:
- 啥都能评 (通用性) :不管是写代码、写小说还是回答安全问题,都得能评,但不同任务的标准差远了,一个固定逻辑很难都评得准。
- 评得准 (准确性) :这是基本要求,但众口难调,标准又多变,保证准确性很难。
- 输入灵活 (灵活性) :有时候评一个答案,有时候比较两个,有时候要给一堆答案排个序,传统 RM 可能只擅长一种。
- 能“进化” (可扩展性) :最头疼的是,很多 RM 裁判,你给它再多时间(计算资源)思考,它打的分基本还是那样,没法通过“多想想”变得更准。我们希望它能像人一样,多花点时间琢磨,判断就能更靠谱,这就是所谓的“推理时可扩展性”。
SPCT 登场:让裁判先定规则再打分
为了解决这些麻烦,DeepSeek 这篇论文《Inference-Time Scaling for Generalist Reward Modeling》就提出了一种新的训练方法,叫 Self-Principled Critique Tuning (SPCT) 。这名字有点长,咱们可以理解为“自定原则、自我点评”的调优方法。
SPCT 主要用在一种叫生成式奖励模型 (Generative Reward Models, GRM) 上。这种 GRM 裁判不直接给分,而是先写一段“点评”(Critique),说明为啥好、为啥不好,最后再从点评里提炼出分数。
SPCT 的核心思想更进一步:它要求 GRM 在写点评之前,先自己想想这次评估应该看重哪些“原则” (Principles) ,比如“代码要简洁”、“回答要诚实”等等,然后再根据这些刚定好的原则去写点评、打分。
热身:常见的“裁判”有几种?
在深入 SPCT 之前,咱们先看看现在主要的几种 RM 裁判范式,以及它们各自的优缺点:
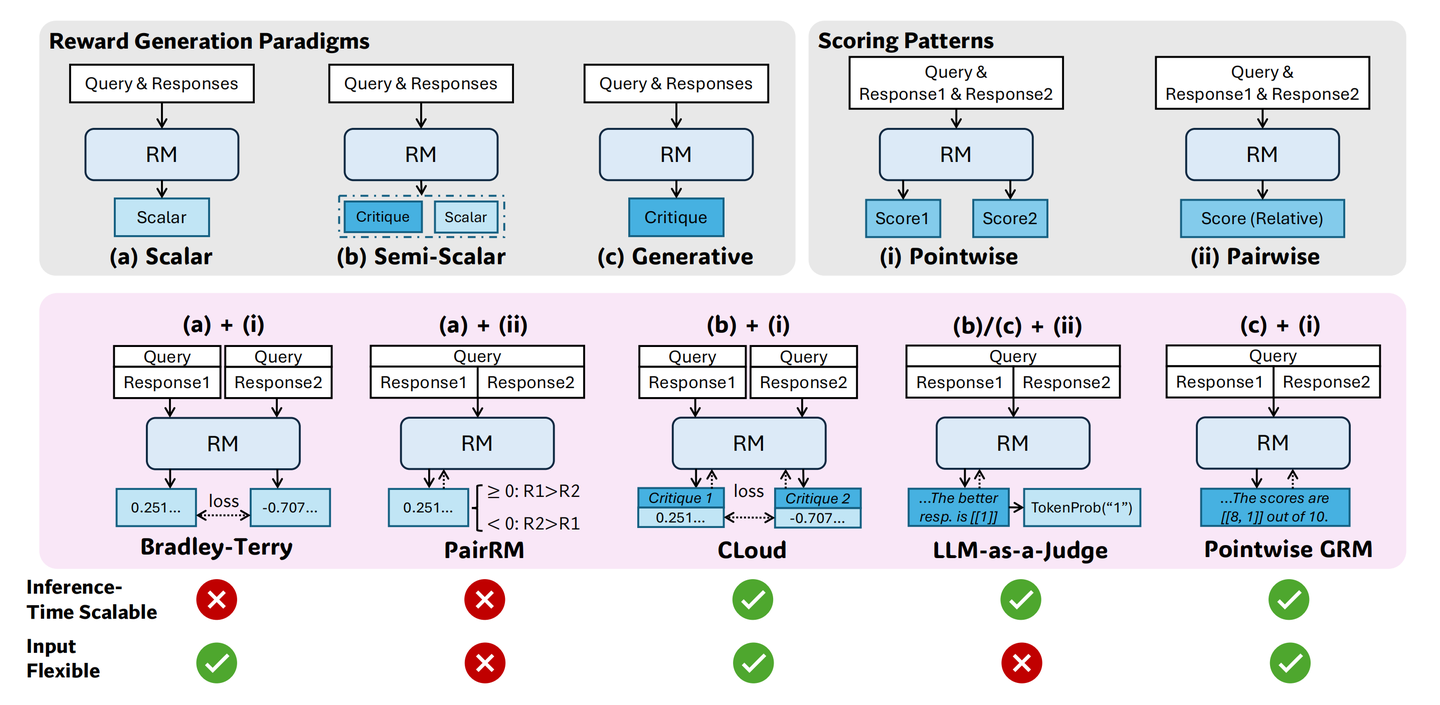
图 2
A. 标量裁判 (Scalar RM)
-
怎么工作:最简单的一种,给它问题 (Query) 和一个或多个回答 (Response),它直接吐出一个或几个分数(标量)。简单粗暴。
-
缺点:
-
黑箱操作:为啥给这个分?不知道,猜不透里面的逻辑。
-
死脑筋:给同样的输入,基本就出同样的分数,想让它多算几次提高准确度?难!缺乏“推理时可扩展性”。
B. 半标量裁判 (Semi-Scalar RM)
- 怎么工作:想结合两边优点,既给分数,也给段文字点评 (Critique)。比如 CLoud 模型。
- 缺点:虽然多了点评,看起来更透明了,但论文觉得,靠它实现推理时性能扩展可能还是差点意思,因为分数那部分可能变化不大。
C. 生成式裁判 (Generative RM, GRM)
- 怎么工作:这位裁判主要靠写“点评” (Critique) 来工作,分数通常是最后从点评文字里提取出来的。
- Pointwise GRM:这是论文和 SPCT 用的基础款。它能给每个回答独立写点评、打分(而不是非要两两比较),所以处理单个、一对、多个回答都很灵活。
- 潜力股:写东西(生成文本)这事儿,天生就有点随机性。这意味着,让它多写几次点评,结果可能不一样。这就为通过采样投票来提升性能(推理时扩展)埋下了伏笔。
SPCT 的“核武器”:不直接打分,先定规则再点评
SPCT 的核心,就是把 RM 的工作流程从“直接给分”变成了“定原则 -> 写点评 -> 提分数”的间接评估。为啥要这么绕一下呢?
为啥间接评估更好?
- “想明白”比“凭感觉”靠谱:直接打分的标量 RM 像个黑箱,逻辑不清晰。SPCT 要求模型先明确“原则”(这次重点看啥),再基于原则写“点评”(分析过程),相当于强制它把思路理清楚。这样做不仅打分更准、更稳(论文里也说了,好原则能提高准确率),而且我们也能看懂它为啥这么评,可解释性大大增强。
- “想法多”才能“集思广益” :标量模型输出固定。但 GRM 生成原则和点评时,可以引入一些随机性(比如调整 temperature 参数)。这意味着,对同一个问题多问几次,它可能会从不同角度(原则侧重不同)给出不同的分析和分数。这种输出的“多样性”,正是后面用投票等方法提升性能的基础。没多样性,投一百次票结果也一样。
- “规则自适应”才能“通吃” :评估任务千变万化,标准也各不相同。SPCT 让模型自己根据当前的问题和回答,动态生成最合适的“原则”。这意味着它能自适应地调整评估重点,这对于打造能胜任多种任务的通用 RM 裁判至关重要。
SPCT 裁判的工作流程
经过 SPCT 训练的 GRM 裁判,是这样评估的:
- 自定原则 (Self-Generated Principles) :拿到问题 Q 和回答{R_i},先生成一套评估原则{p_j},可能还带点权重啥的。
- 生成点评 (Critique Generation) :然后,根据自己刚定的原则{p_j},给每个回答 R_i 写详细的分析报告,也就是点评 C。
- 提取分数 (Score Extraction) :最后,用一个解析工具,从点评 C 里把每个回答 R_i 的分数{S_i} 给扒出来。
对比一下:直接打分 vs. SPCT 间接打分

区别很明显,SPCT 多了中间“定原则”和“写点评”两步,让整个评估过程更结构化、更透明了。
SPCT 是怎么炼成的:两阶段训练法
SPCT 的目标是训练出一个既能生成高质量原则和点评,又能导出准确分数,还具备良好扩展性的 GRM。训练分为两个阶段:
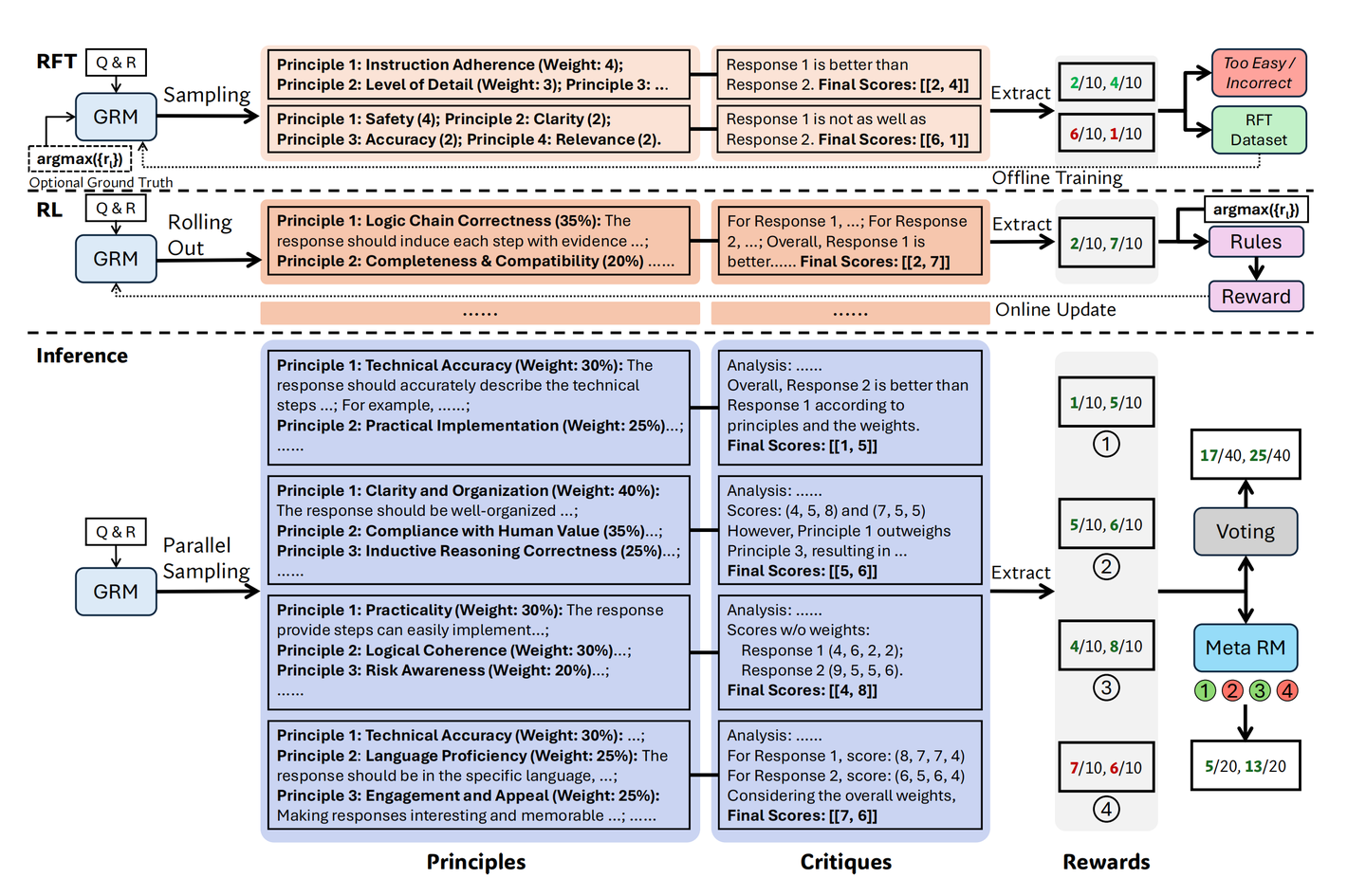
图 3
训练目标是啥?
教会 GRM 不仅能按格式输出原则、点评和分数,而且这些输出要能帮它做出和“标准答案”(Ground Truth)一致的判断。
阶段一:拒绝式微调 (RFT - 先热个身)
-
目的:让预训练好的 GRM 先熟悉一下生成原则、点评、分数的套路,并能处理不同数量的输入(单个、多个回答)。
-
过程:
-
试着评:拿 RM 数据集里的问题和回答 (Q, Ri),让 GRM 多试几次(N_RFT 次),每次都生成原则、点评和分数{S_i}。
-
挑三拣四(拒绝策略) :比较 GRM 给的分数{S_i}和数据集里的标准答案(偏好 {r_i})。
- 如果评错了(比如把差的说成好的),这次尝试就不要(标记 “Incorrect”)。
- 如果对某个问题,试了 N_RFT 次全都评对了,说明太简单了,也不要(标记 “Too Easy”)。
- 用好的练:把那些评对了、但又有点难度的尝试(被接受的样本)收集起来,组成 RFT 数据集,用标准的监督学习方法微调 GRM。
阶段二:基于规则的在线强化学习 (Rule-Based Online RL - 实战提升)
-
目的:进一步打磨 GRM,让它更倾向于生成那些能导出正确评估结果的原则和点评。特别是要提升它通过多次尝试(采样)来提高判断准确度的能力(即可扩展性)。
-
过程:
- 再评一次 (Rollout) :模型拿到 (Q, {R_i}),走一遍流程:生成原则 -> 生成点评 -> 提取分数 {S_i}。
- 给奖惩 (奖励信号计算) :比较模型预测的分数/排序 {S_i} 和标准答案 {r_i},根据一个简单规则(论文公式 5)给个奖励 r。
- 更新模型:用在线强化学习算法(比如 GRPO),根据这个 +1 或 -1 的奖励信号来更新 GRM 的参数,鼓励它多生成能拿 +1 分的原则和点评。
论文中的奖励规则(公式 5)
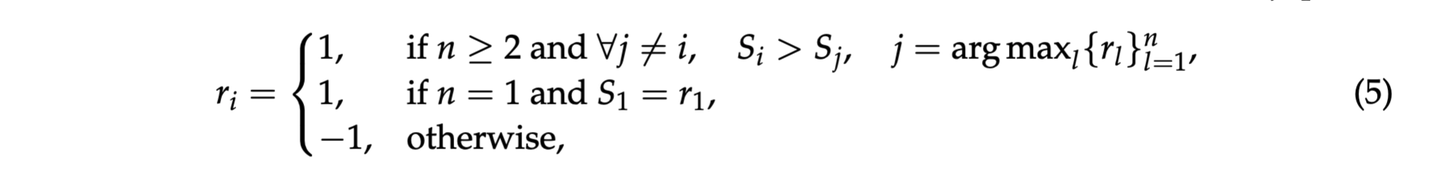
公式 5
奖惩规则(以评多个回答为例) :
-
先找到标准答案里最好的那个回答,假设是 R_j。
-
看模型预测的分数 {S_i}:
-
如果模型也认为 R_j 是最好的,而且是唯一最好的(S_j 比其他所有 S_i 都大),那就给个奖励 r = +1(评对了!)。
-
其他情况(比如选错了最好的,或者打平了分不出哪个最好),都给个惩罚 r = -1(评错了!)。
例子:标准答案是 R2 比 R1 好。
- 模型预测 [[6, 8]] (S2 > S1),奖励 +1。
- 模型预测 [[7, 5]] (S1 > S2),奖励 -1。
- 模型预测 [[7, 7]] (S1 = S2),奖励 -1。
SPCT 效果怎么样?优势在哪?
经过 SPCT 训练出来的 DeepSeek-GRM 模型,确实有几把刷子:
更准、更稳
强制模型先想原则再点评,减少了瞎猜和偏见,评估结果自然更准确、更可靠。
能“越算越准” (推理时扩展性)
这是 SPCT 的核心亮点!训练好的 GRM,可以在用的时候通过多花点计算资源来提升性能:
-
多问几次 (采样机制) :对同一个问题和回答 (Q, {R_i}),让模型独立地、带点随机性地(比如 temperature > 0)思考 k 次。因为想法(生成过程)有多样性,每次可能会得到不同的原则、点评和分数。
-
汇总意见 (聚合机制) :
- 简单投票 (Voting) :最直接的方法,把 k 次采样得到的每个回答的分数加起来或取平均,得到最终总分。谁总分高就选谁。比如图 3 里的例子,4 次采样 R1/R2 得分分别是 [1, 5], [5, 6], [4, 8], [7, 6],投票结果 R1=17, R2=25,最终选 R2。
- 精英投票 (Meta RM 引导 - 可选) :更高级的玩法,可以再训练一个“裁判的裁判” (Meta RM),专门评估每次采样生成的 (原则,点评) 的质量。投票时,只选那些 Meta RM 评分最高的 k_meta 次采样的结果来汇总,把质量差的意见过滤掉。如图 3,Meta RM 可能筛掉一些低分采样再投票。
论文里的实验结果(如图 1)清楚地显示,随着采样次数 k 增加,不管是简单投票还是精英投票,DeepSeek-GRM 的性能都蹭蹭往上涨,证明了它确实能有效地“越算越准”。
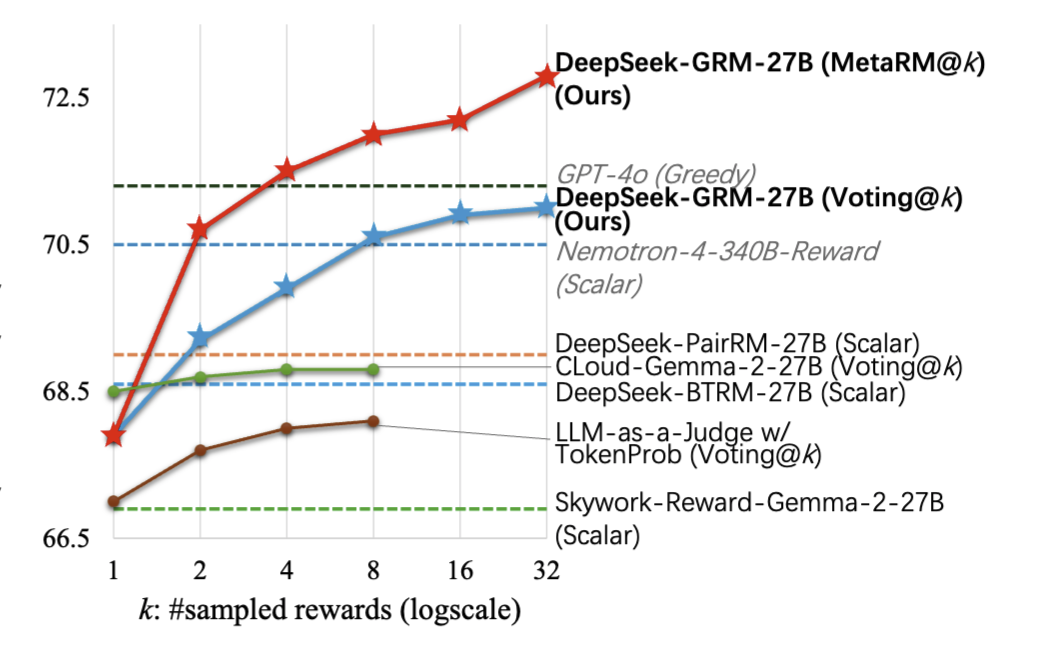
图 1
更透明、更灵活
生成的原则和点评让我们能看懂模型为啥这么打分,不再是黑箱了。同时,Pointwise GRM 的形式让它处理单回答、双回答、多回答排序等各种情况都得心应手。
更通用
模型能根据输入自适应地调整评估原则,让它在不同领域、不同类型的任务上表现更好,通用性更强。
眼见为实:看个例子
论文附录 F 的表 17 是个很好的例子,展示了 DeepSeek-GRM-27B 在评代码任务时是怎么“越算越准”的:
-
问题:一个编程题和两个代码答案 (R1, R2)。
-
第 1 次思考 (采样 1) :模型定了些原则(代码正确性、初始化、循环逻辑等),分析后打分 (R1, R2) -> [8, 8],Meta RM 觉得这次思考一般般,评分 -15.78。

- 第 2 次思考 (采样 2) :这次原则侧重变了(代码正确性、可读性、边界条件等),打分 (R1, R2) -> [5, 9](注意:例子中输入顺序颠倒,这里已调整回原始顺序),Meta RM 觉得这次还行,评分 1.31。

- 第 3 次思考 (采样 3) :又换了些原则,打分 (R1, R2) -> [7, 10],Meta RM 觉得这次最好,评分 1.67。

-
汇总结果:
-
简单投票:三次得分 (8, 8), (5, 9), (7, 10)。R1 总分 = 8+5+7 = 20。R2 总分 = 8+9+10 = 27。 最终选 R2。
-
精英投票 (k_meta=2) :选 Meta RM 评分最高的第 2、3 次思考结果。得分 (5, 9), (7, 10)。R1 总分 = 5+7 = 12。R2 总分 = 9+10 = 19。 最终也选 R2。
这个例子很直观地展示了:多想几次(采样)确实能带来不同的视角(原则)和结果,通过汇总(投票)就能得到更稳健的最终判断。
总结:SPCT,让 RM 裁判更智能
总的来说,SPCT 是个挺有创意的 GRM 训练方法。它通过让模型学会“先定规则、再点评打分”的模式,实打实地提升了奖励模型的准确性、透明度、灵活性和通用性。最关键的是,它训练出的 GRM 具备了出色的推理时可扩展性——可以通过多花算力来换取更高的评估质量。
SPCT 证明了 GRM 在打造下一代通用、可扩展奖励模型方面的巨大潜力。这种能“讲道理”、还能通过“多琢磨”提升判断力的 RM 裁判,对于训练出更强大、更可信的 LLM 来说,至关重要。
论文也提到,未来可以继续优化 GRM 的效率,或者让它学会使用工具来处理更复杂的评估任务。怎么把这种可扩展的 RM 更有效地用到 RL 训练中,也是个值得研究的方向。