SQL 的诞生
SQL 英文全称是 Structured Query Language,中文名即结构化查询语言,是一门专门用来查询数据的声明式编程语言。
我先解释一下声明式语言的概念,编程语言有两个分类:
-
命令式:手把手教机器做事情
-
声明式:告诉机器任务,让它自己想办法解决
举个例子,假设你家里有机器人,你想让它帮忙拿一个在客厅桌子上的白色杯子给你。
如果用命令式编程的方式来实现,你需要给机器人输入指令:把第一个房间的第二个家具上的第五个东西拿给我。然后机器人会按照你的指示先找到第一个房间,然后找到第二个家具,最后再找到第五个东西。
如果是用声明式编程的方式来实现,你只会说:帮忙拿一下客厅桌子上面的白色杯子给我。然后机器人就会先找到客厅对应的房间编号,再找到桌子对应的编号,最后找到白色杯子对应的编号,然后根据编号去找对应的东西。
上面哪张方式对人来说更简单呢?显然是第二种,第一种你需要告诉机器人具体怎么做,第二种你只需要说出你要想的结果。
回到我们 SQL 查询的主题上,假设现在给你一个文件,里面包含了 100 个人的姓名和性别,让你从里面查找李四的性别。数据格式如下:
| name | gender |
|---|---|
| 张三 | 男 |
| 李四 | 女 |
| 王五 | 男 |
| … | … |
在没有 SQL 之前,我们是用命令式编程的方式来手把手教机器完成一次查询的,如下面的代码所示:
String findGenderByName(List<Person> persons, String name) {
for (Person person: persons) {
if (person.getName().equals(name)) {
return person.getGender();
}
}
return null;
}可以发现用命令式编程的方式在面对海量的查询需求时,需要编写很多的类似的代码。比如根据某个字段进行过滤是一个通用查询需求,但是如果用命令式编程的语言来写,换一个数据模型就需要重新开发类似的代码。当然聪明的程序员会想到用泛型来解决这个问题,但是针对这种非常通用的场景,有没有更好的方案呢?
答案是肯定的,那就是针对数据查询定义一门领域语言,而且是声明式的。SQL 的出现使得声明式查询成为可能,让查询场景的编程门槛大大降低了。要查询李四的性别,只需要将上面的数据导入到数据库中,然后执行下面的 SQL 语句:
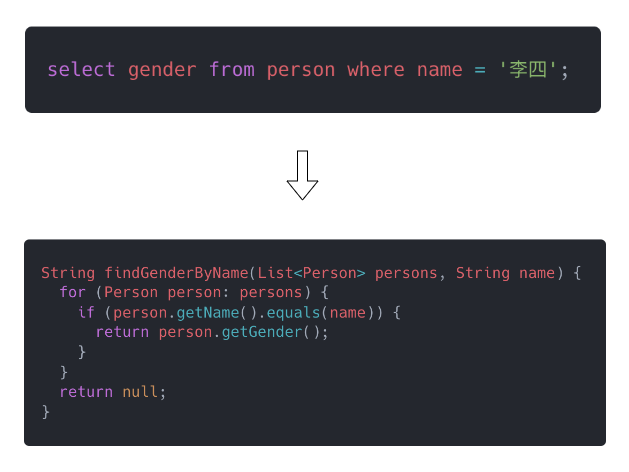
select gender from person where name = '李四';SQL 的语法相比 Java 等语言要简单得多,使得复杂查询的代码编写工作量大大减少了,从上面的查询语句示例可以看到,SQL 的代码量远远少于 Java。此外,SQL 是面向查询场景的领域语言,降低了查询数据的编程门槛,你不需要为了查询数据专门去学 Java,只需要学一下 SQL,即使是运营和产品也能够掌握。
Calcite 的诞生
一直以来 SQL 都是关系型数据库的专属,后来随着 NoSQL 数据库的发展,大家发现关系型数据库虽然有局限,但是 SQL 本身是个好东西,因为 SQL 极大的降低了查询数据库门槛。所以很多 NoSQL 都开始支持 SQL 查询。大部分的 NoSQL 只支持简单的基于 key 的查询,而 SQL 的查询能力无疑是强大的,那么从 KV 查询到 SQL 查询中间的鸿沟要如何跨越呢?Calcite 这个开源项目就给出了答案。Calcite 是一个支持异构数据源的 SQL 查询框架,它只专注于 SQL 的查询和优化,数据引擎交给使用方自定义。也就是说任何 NoSQL 数据库可以只要实现了 Calcite 的数据源适配器,就能直接支持 SQL 查询。
举一个简单的例子,基于 Calcite 框架,我们只要实现了 CSV 文件的适配器,就能在 CSV 文件上面使用 SQL 来查询。这是一个 Calcite 的官方例子。首先引入包:
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-core</artifactId>
<version>1.31.0</version>
</dependency>
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-example-csv</artifactId>
<version>1.21.0</version>
</dependency>下面是一个公司职员的 CSV 表格,Calcite 提供了一个 CSV 的适配器,基于这个适配器可以直接在 CSV 文件上面支持 SQL 查询。下面的文件放到 resource/sales 的目录下面,命名为:EMPS.csv。
EMPNO:int,NAME:string,DEPTNO:int,GENDER:string,CITY:string,EMPID:int,AGE:int,SLACKER:boolean,MANAGER:boolean,JOINEDAT:date
100,"Fred",10,male,,30,25,true,false,"1996-08-03"
110,"Eric",20,"M","San Francisco",3,80,,false,"2001-01-01"
110,"John",40,"M","Vancouver",2,,false,true,"2002-05-03"
120,"Wilma",20,"F",,1,5,,true,"2005-09-07"
130,"Alice",40,"F","Vancouver",2,,false,true,"2007-01-01"然后是 CSV 数据库的 schema 定义,这个放到 resource 目录下面,命名为:model.json
{
"version": "1.0",
"defaultSchema": "SALES",
"schemas": [
{
"name": "SALES",
"type": "custom",
"factory": "org.apache.calcite.adapter.csv.CsvSchemaFactory",
"operand": {
"directory": "sales"
}
}
]
}最后是一段测试代码:
public class CalciteTest {
public static void main(String[] args) throws SQLException {
String sql = "select gender from SALES.EMPS where name = 'Fred'";
String model = "/model.json";
Properties info = new Properties();
info.put("model", CalciteTest.class.getResource(model).getPath());
try (Connection connection = DriverManager.getConnection("jdbc:calcite:", info)) {
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
String gender = resultSet.getString("gender");
System.out.println(gender);
}
}
}
}
可以看到只要使用了 CSV 文件的 Calcite 适配器,就可以直接把 CSV 文件当做关系数据库使用 SQL 来进行查询。
SQL 查询的实现原理
那么问题来了,Calcite 是怎么做到的让 CSV 文件也能当成关系型数据库用 SQL 来查询的呢?我们自己可以推演一下,要实现 SQL 查询功能需要做哪些事情。一个很简单的想法就是实现一个编译器,将 SQL 语句直接编译成机器码,就像 C 语言用 GCC 编译成机器码一样。这种实现方式难度比较高,你需要精通编译原理。如果我只会 Java,那要怎么实现这个 SQL 查询引擎呢?可以参考 Java 的思路,Java 也不是直接编译成机器码执行的,而是编译成字节码,然后再让字节码在 JVM 上面执行。那么我们也可以将 SQL 先编译成 Java 代码,然后再执行。如下图所示:
想法看起来很美好,但是怎么实现呢?Calcite 这个项目给了我们答案,它将这个过程分为了三步:
-
将 SQL 语句使用 JavaCC 解析成 SQL 对象。
-
要把查询请求转化成逻辑计划。
-
把逻辑计划进行优化,并且生成物理计划。

看到这里一下子引入了很多没听说的概念,你可能已经晕了,没关系,接下来我就按顺序逐个解释一下。
SQL 解析
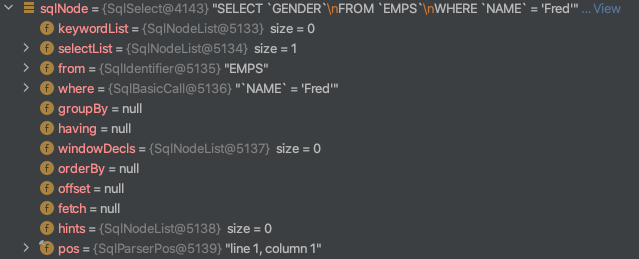
首先是 SQL 解析做了啥。既然是用 Java 来实现 SQL 查询的功能,那么肯定第一步是要对 SQL 查询进行建模,一切的逻辑都围绕这个 SQL 对象展开。如下图所示,这个就是我们例子中查询语句生成的 SqlNode 对象。可以看到,这个对象就是将 SQL 语句结构化了,对 SQL 的各个部分都定义了相应的对象,比如 where 的查询条件定义成了 SqlBasicCall 对象。通过将 SQL 语句解析成对象,我们就可以围绕这个对象编写相应的处理逻辑。
Calcite 直接复用了 JavaCC 编译器的能力来构建 SQL 解析器,因为编译器是一个非常成熟的领域,没有必要重复造轮子。关于 JavaCC 的使用我这里就不展开了,你如果感兴趣可以去网上搜索相关的内容,这里只需要知道 SQL 对象的解析是使用 JavaCC 做到的就足够了。
逻辑计划与关系代数
有了 SQL 对象之后,下一步就是基于 SQL 对象生成逻辑计划。SQL 是基于关系代数设计出来的语言,所以它需要先翻译成关系代数的逻辑结构,这个逻辑结构跟关系代数的数学形式是等价的。
下面是关系代数与 SQL 语法的对照表,比较大的不同就是 SQL 中的 select 在关系代数中叫 project,where 在关系代数中叫 select。
| 名称 | 英文 | 符号 | 说明 |
|---|---|---|---|
| 选择 | select | σ | 类似于 SQL 中的 where |
| 投影 | project | Π | 类似于 SQL 中的 select |
| 并 | union | ∪ | 类似于 SQL 中的 union |
| 笛卡儿积 | Cartesian-product | × | 类似于 SQL 中不带 on 条件的 inner join |
| 自然连接 | natural join | ⋈ | 类似于 SQL 中的 inner join |
那么关系代数有啥用呢?听到代数这个词你可能会闻到一股数学的味道,实际上关系代数就像线性代数一样属于数学领域,线性代数是研究如何高效的解决线性问题,类似的,关系代数是就研究如何高效的解决查询问题。关系代数定义了查询问题中的运算符号,如上面的表格所示,同时还有运算规律,例如连接与笛卡尔积结合律、连接与笛卡尔积交换律。通过这些运算规律,我们可以对查询操作进行等价变换,从而找到更加简单高效的解法。这里我们不上数学课,所以我只简单举一个选择操作下移的等价变换例子。
假设我们有一个 SQL 请求:
SELECT A.a1 FROM A, B, C WHERE A. a1 =C. a1 AND B. b1 =C. b1 AND f(c1)翻译成关系代数
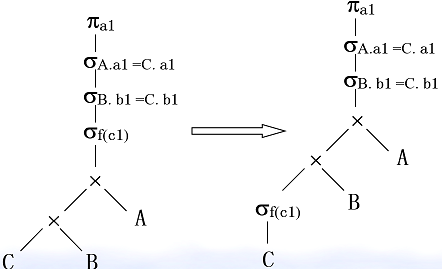
左边的关系代数指的是从 A、B、C 三个表做笛卡尔积之后,再执行三次条件判断,首先是 f(c1),表示对 c1 字段执行一个 f 布尔函数,然后是判断 B.b1=C.b1,最后是 A.a1=C.a1。
右边是经过等价变换之后的关系代数,把 f(c1) 的条件判断移到了 C 执行笛卡尔积之前,这里很容易看出来,这样查询的结果是等价的,但是查询的性能肯定是右边的更高,因为在 B 和 C 笛卡尔积之前就先对 C 进行过滤操作,这样能够减少笛卡尔积的数据量。
到这里你应该知道为什么要先将 SQL 翻译成关系代数(逻辑计划),而不是直接生成可执行的代码了。在上面的例子,如果我们直接将 SQL 翻译成可执行的代码,那么显然查询性能会很差,浪费了资源。如果我们先翻译成关系代数,就能利用关系代数对查询操作进行优化,从而提高查询的效率。
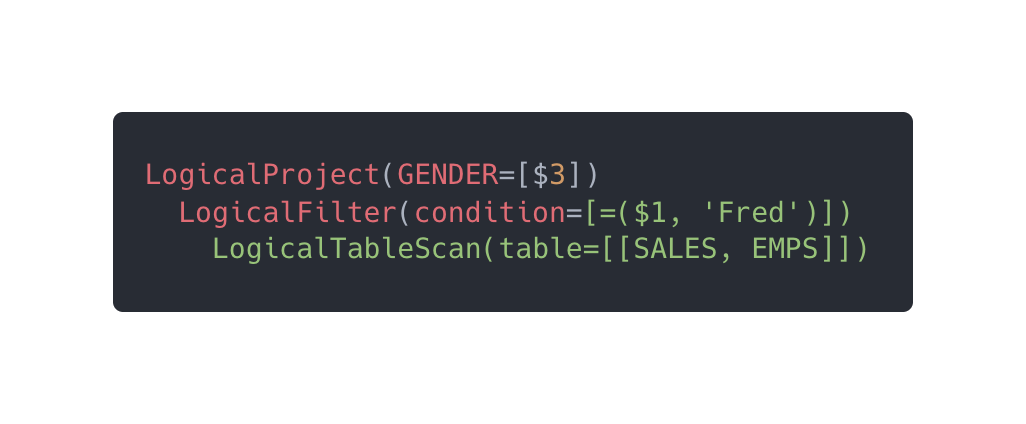
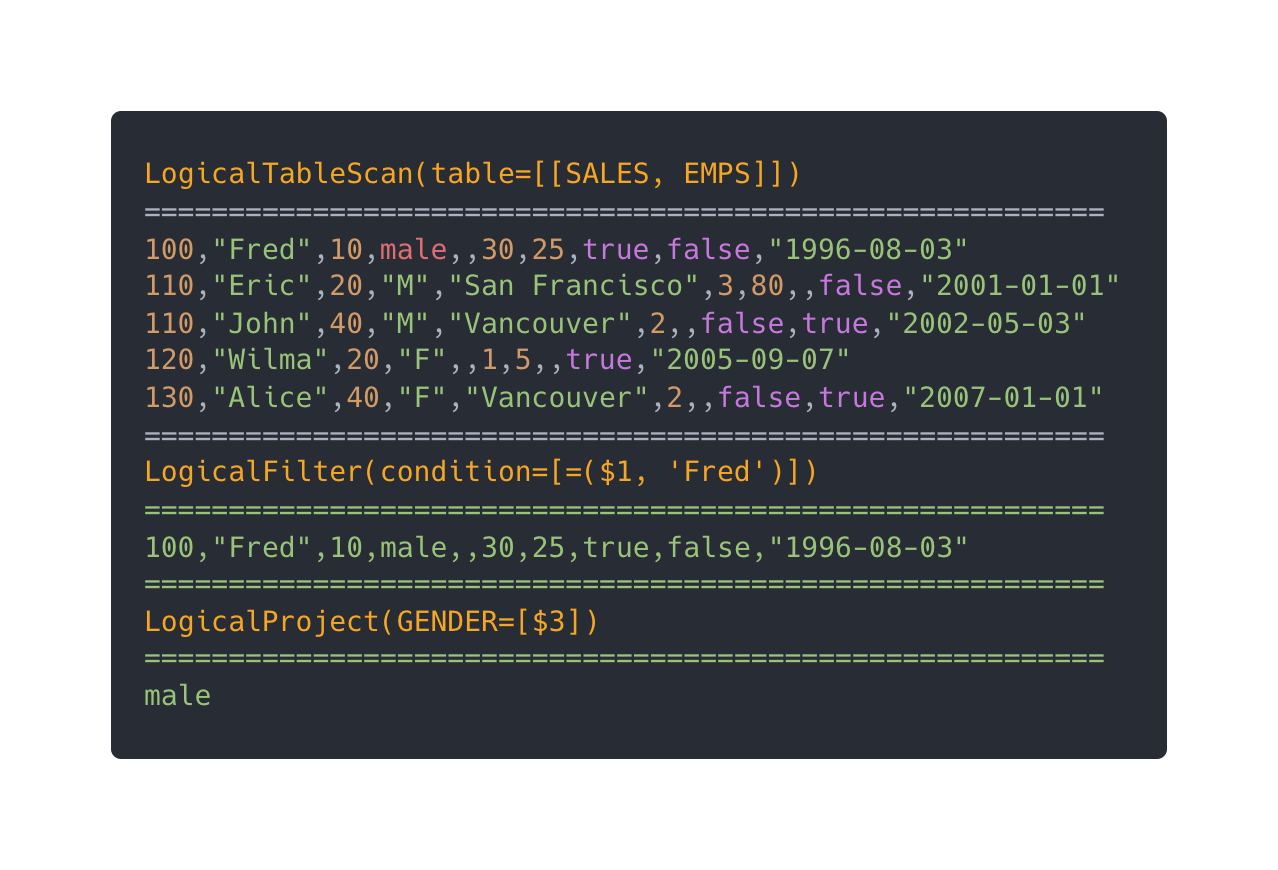
回到我们的例子,前面的查询性别的 SQL:select gender from SALES.EMPS where name = 'Fred'被翻译成下面的逻辑计划。
-
LogicalProject 是选择操作,也就是选择 GENDER 这个字段,因为 GENDER 字段在 CSV 表中是第三个字段,所以用$3指代。
-
LogicalFilter 是过滤操作,比较条件为”=(1, ‘Fred’)1 是 NAME 在表中的位置。
-
LogicalTableScan 是扫描操作,也就是扫描 EMPS 表,SALES 是数据库名。
逻辑计划的执行是自底向上的,整个逻辑计划翻译成大白话就是把 EMPS 表所有数据查询出来,然后执行过滤操作把姓名为 Fred 的数据记录查询出来,最后在数据记录只选择第三个字段(性别)作为结果返回。
物理计划与代码生成
有了逻辑计划之后,我们就可以基于逻辑计划进行优化并且生成物理计划了。下面是逻辑计划经过优化之后生成的物理执行计划。
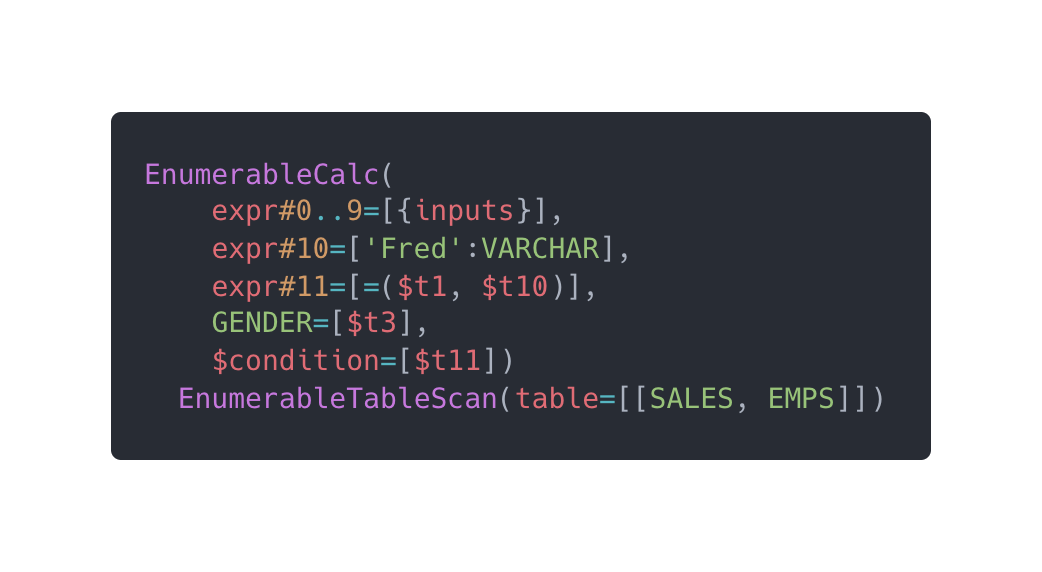
可以看到,逻辑计划原来是有三个操作的,这里被优化成了两个操作:
-
EnumerableCalc(可枚举计算):这个是 Calcite 的计算算子,括号里面是它的逻辑语法。回顾一下我们的 SQL:
select gender from SALES.EMPS where name = 'Fred' -
expr#0..9=[{inputs}]:数据表的字段分别被映射为 0~9 的 10 个字段,这里表示输入参数的第 0 到 9 是数据表的输入字段,比如:t0 表示 EMPNO -
expr#10=['Fred':VARCHAR]:这里用 t10 表示 SQL 中的'Fred' -
expr#11=[=($t1, $t10)]:这里表示一个等于的函数表达式,指代了name = 'Fred',t1 是 NAME 字段,t10 前面说了是Fred的字符串 -
GENDER=[$t3]:进行 select(选择字段)的操作,表示输出结果中的 GENDER 从计算结果中的 t3 字段获取 -
$condition=[t11]:即 where 操作,这里的 where 条件是 t11 表达式,即expr#11=[=($t1, $t10)]也就是name = 'Fred' -
EnumerableTableScan(可枚举表扫描):前面的算子是进行计算,但计算需要要输入数据,输入数据就通过这个算子来提供。
-
table=[[SALES, EMPS]]:这里表示从 SALES 库中的 EMPS 表中获取所有数据。
总结一下逻辑计划到物理计划的过程,逻辑计划是完全按照关系代数的方式来描述的,并且还没有经过优化。而物理计划是完全按照实际执行时来分配算子的。在上面的例子,逻辑计划的选择和过滤操作在物理计划中被合并成为了一个 EnumerableCalc 算子。
EnumerableCalc 算子的设计很巧妙,可以拿 CPU 来类比,你可以把 t1~t11 当做是寄存器,操作指令只会从寄存器中获取数据计算,并且把计算结果放回寄存器,这样就不需要像 Java 编程一样用变量名称来指代要操作的数据,更加灵活。
但这里有一个问题还悬而未决,那就是寄存器有了,那么操作指令从哪里来的呢?我们写 SQL 的时候可没有告诉计算机要怎么进行条件判断。
答案是 Calcite 是使用代码生成技术对每个算子都生成一段 Java 代码,这段代码就是对数据的操作指令。下面的代码就是前面 EnumerableCalc 算子对应的 Java 代码。
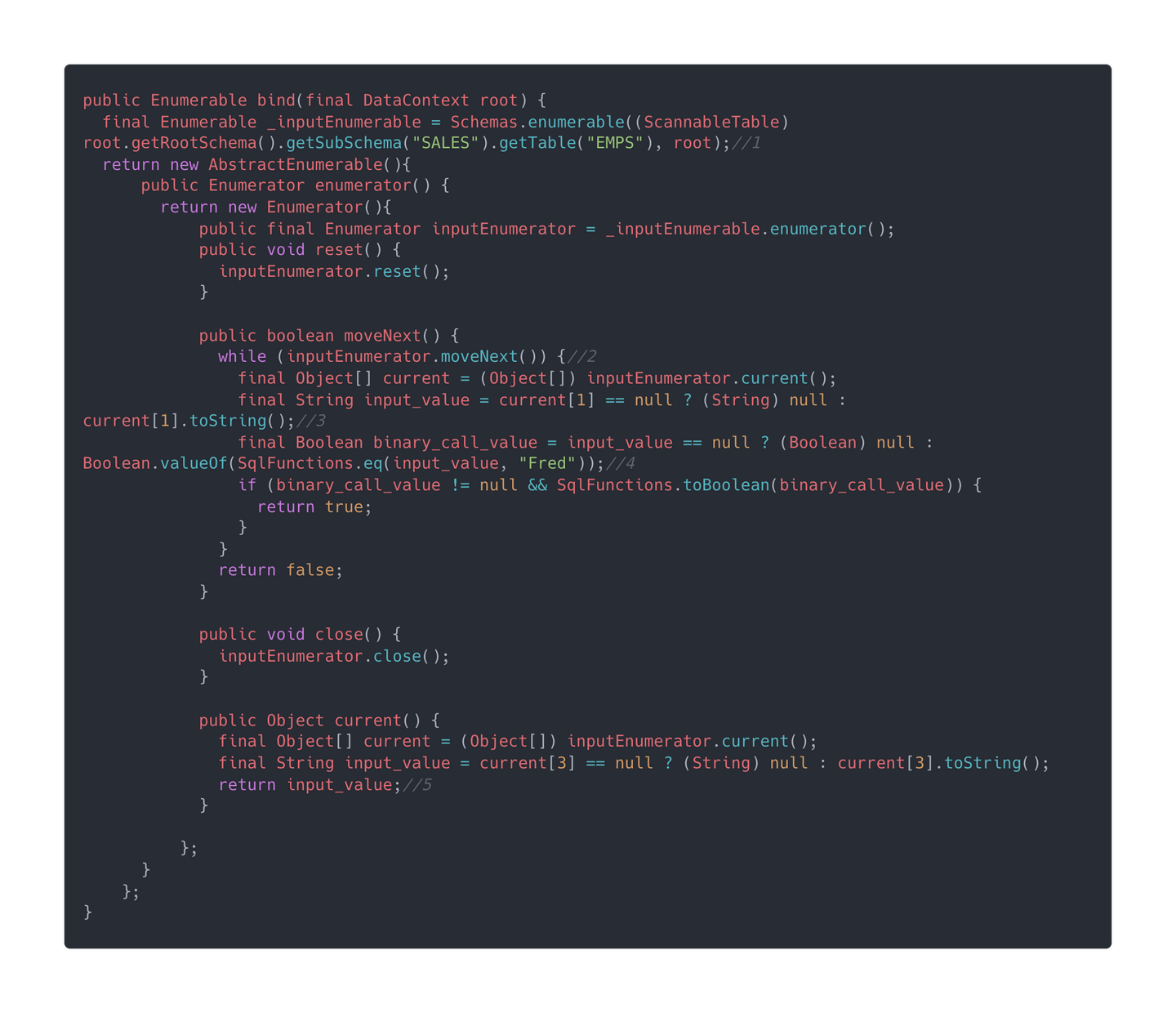
这里先简单说一下代码的逻辑:
-
获取数据表的迭代器作为数据输入,对应了
from SALES.EMPS -
对数据进行遍历操作
-
获取 t1 的数据
-
将 t1 的数据跟字符串
Fred进行比较,如果相等就直接返回,如果不相等就继续循环直到找到相等数据或者遍历完数据,对应了name = 'Fred' -
这里是 Enumerable 迭代器获取当前数据的方法,可以看到它是从完整的数据行里面获取到 t3(GENDER)的数据返回,对应了
select gender
在了解了 EnumerableCalc 算子是怎么实现了之后,我们再来看一下 EnumerableTableScan 是怎么实现的。
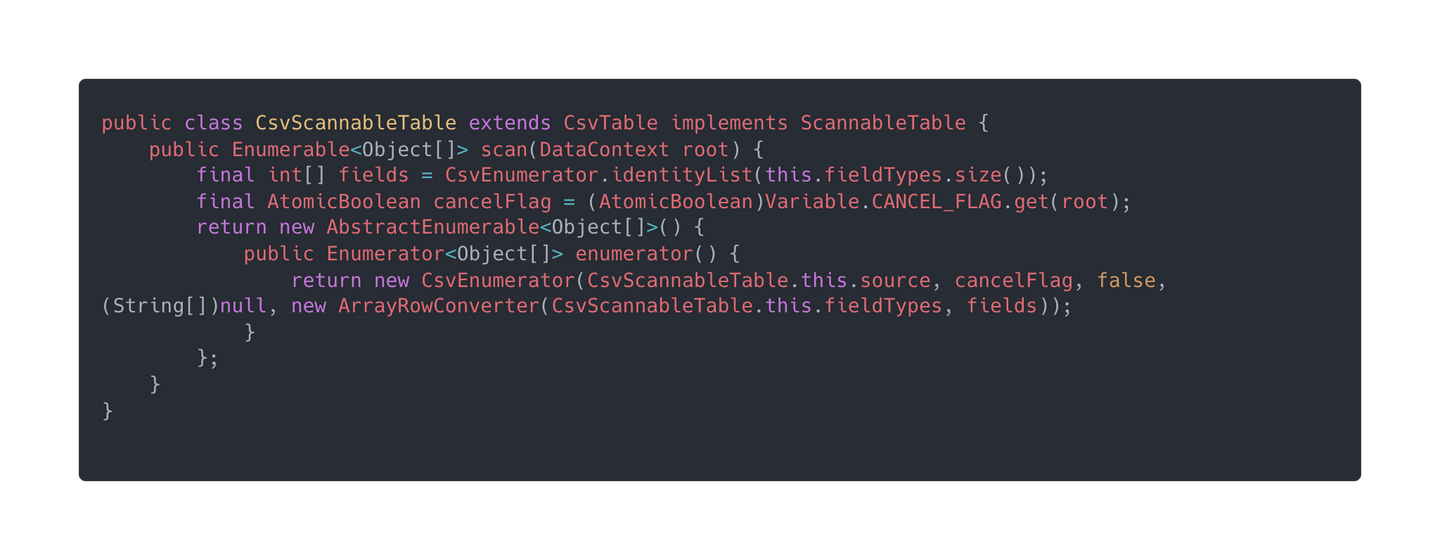
EnumerableTableScan 实际上被翻译成了Enumerable _inputEnumerable = Schemas.enumerable((ScannableTable) root.getRootSchema().getSubSchema("SALES").getTable("EMPS"), root),并没有像 EnumerableCalc 一样生成一份代码。上面的代码实际上就是获取了ScannableTable之后将数据表封装成了Enumerable数据迭代器。Calcite 提供的 CSV 例子中,CsvScannableTable就是实现了ScannableTable。
下面是CsvScannableTable的代码,它实现了ScannableTable的接口,主要就是Enumerable<Object[]> scan(DataContext root)方法,这个方法就是返回一个能够把 CVS 文件中的数据都遍历一遍的迭代器。在上面 EnumerableCalc 的_inputEnumerable实际获取到的就是CsvScannableTable.scan方法返回的Enumerable。
进阶用法:可过滤的数据源
到这里,基于 CSV 的文件 SQL 查询原理就讲解完毕了。你可能还有一个疑问:实际问题并不像上面例子这样数据量很小可以全表扫描返回结果,遇到数据量大的情况怎么办呢?Calcite 当然也考虑到了这种情况,解决方法就是提高一个支持过滤条件的数据源接口:FilterableTable,FilterableTable的方法是:Enumerable<@Nullable Object[]> scan(DataContext root, List<RexNode> filters);,相比ScannableTable的方法多了一个filters的字段。filters是 Calcite 通过解析 SQL 得到的查询条件,一般来说 NoSQL 数据库至少也会支持基于 Key 的索引查询,你可以使用filters在真实数据源上进行过滤之后再返回,这样可以大大减少返回给 Calcite 的数据量。
下面我们来看一下当 CSV 文件实现了FilterableTable接口之后的查询过程,在 model.json 文件中新增:"flavor": "FILTERABLE",表示对 CSV 文件使用支持FilterableTable的数据源实现。
{
"version": "1.0",
"defaultSchema": "SALES",
"schemas": [
{
"name": "SALES",
"type": "custom",
"factory": "org.apache.calcite.adapter.csv.CsvSchemaFactory",
"operand": {
"directory": "sales",
"flavor": "FILTERABLE"
}
}
]
}然后执行同样的代码,看看生成的逻辑计划和物理计划有没有变化。
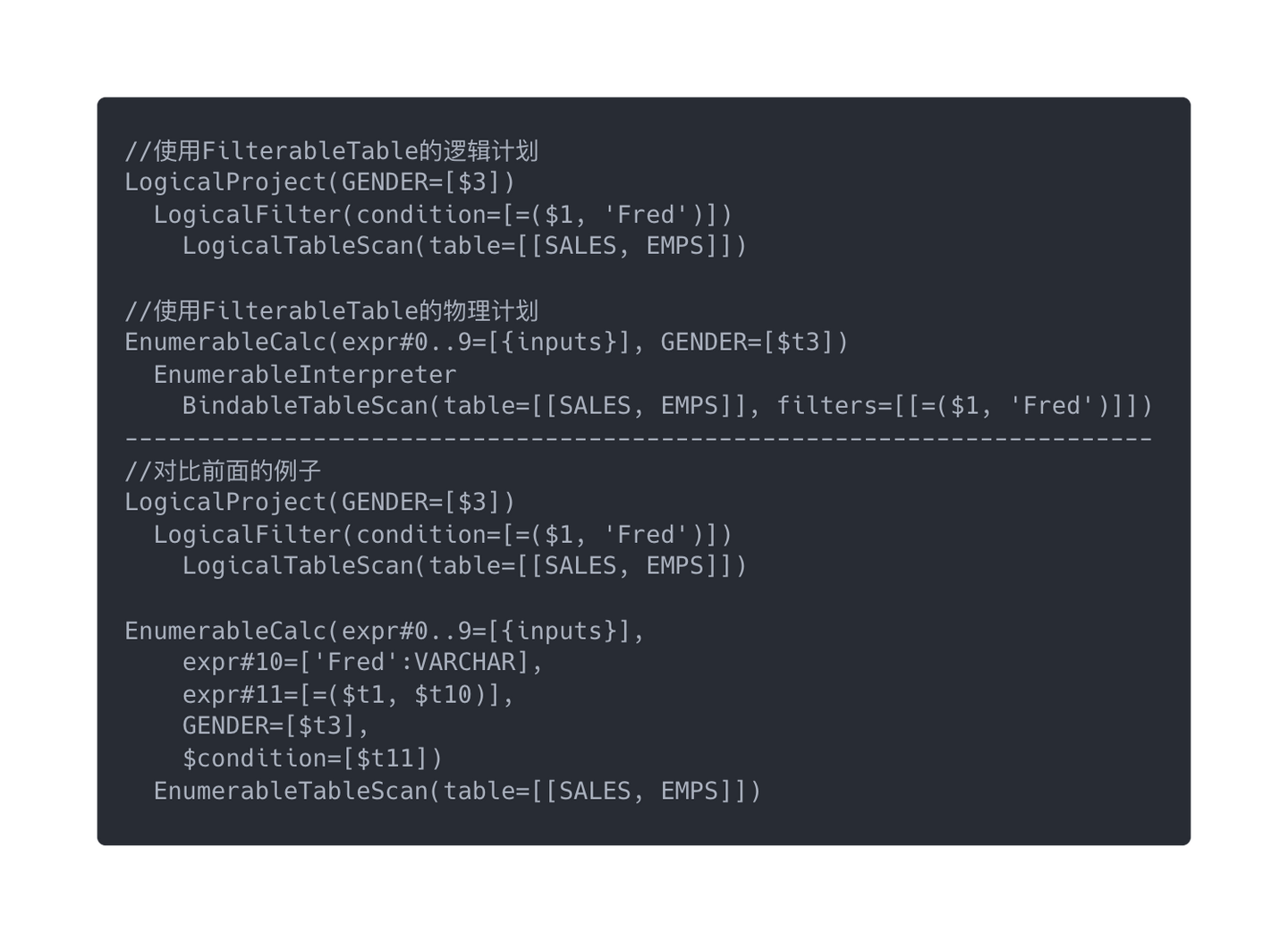
从上面的图片可以看到,逻辑计划跟之前相比没有变化,而物理计划则有很大的变化。
首先是 EnumerableCalc 的入参少了条件判断,然后 EnumerableTableScan 变成 EnumerableInterpreter 和 BindableTableScan。
EnumerableCalc 的变化是因为我们提供了支持条件过滤的数据源,所以在逻辑计划优化成物理计划的时候,Calcite 的优化器使用了关系代数中的谓词下推,即将查询条件下放到 TableScan 的时候,这个逻辑也很好理解:比起全表扫描然后在内存中过滤,使用谓词下推将查询条件放到扫描数据阶段,可以使得返回的数据量减少从而提升查询效率。因此 EnumerableCalc 的条件过滤逻辑被下放到了 BindableTableScan 阶段。
EnumerableTableScan 的变化是因为谓词下推的优化时查询条件的入参是动态变化,没有全表扫描那么简单,EnumerableCalc 代码生成的时候不能直接写死,需要通过 EnumerableInterpreter 解释器进行解释执行来获取 BindableTableScan 的内容。看一下生成的代码会比较直观:
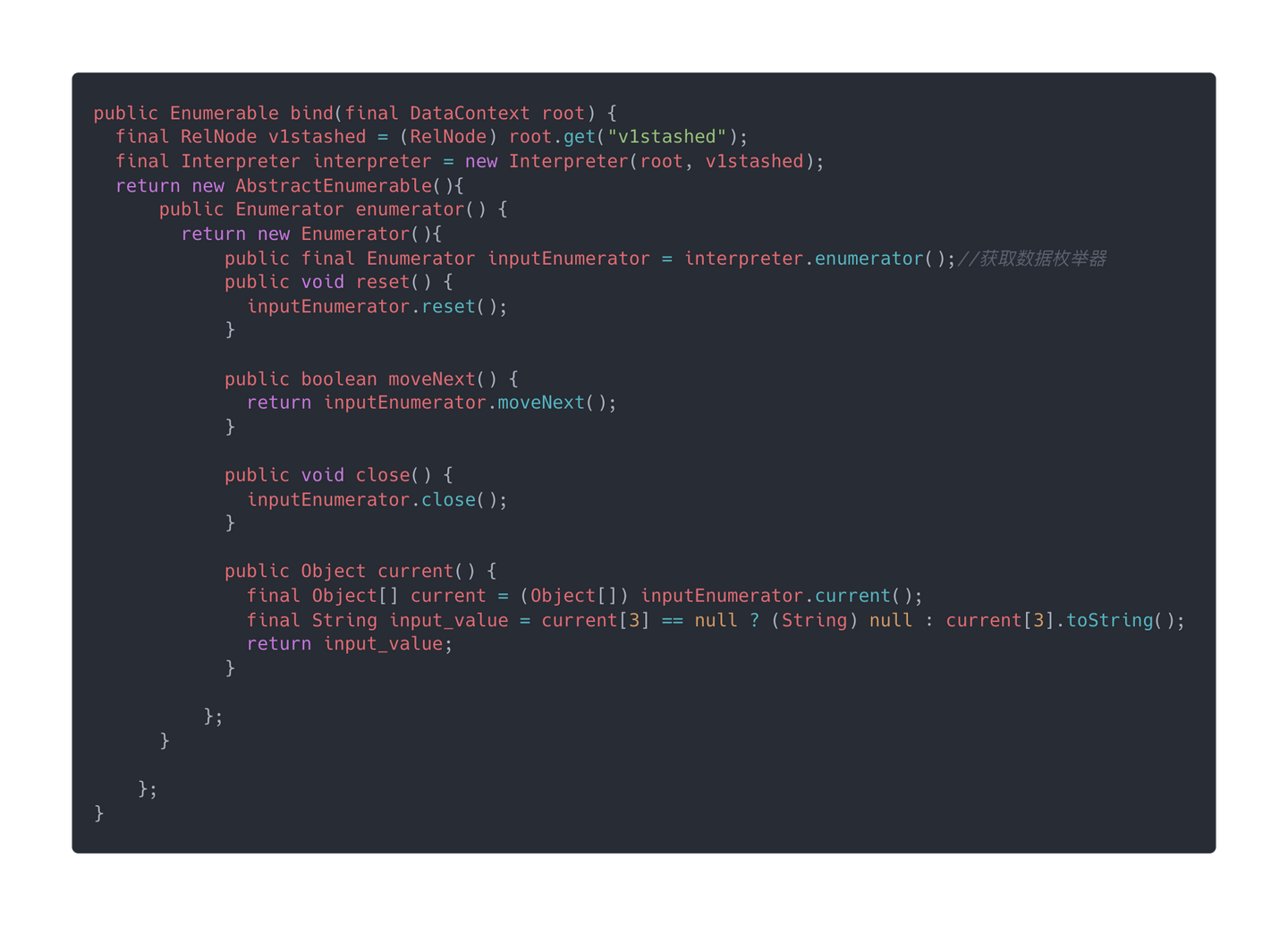
可以看到,这次 EnumerableCalc 生成的代码里面获取 Enumerable 数据迭代器的方式是:Enumerator inputEnumerator = interpreter.enumerator();,而不是像之前一样:Enumerable _inputEnumerable = Schemas.enumerable((ScannableTable) root.getRootSchema().getSubSchema("SALES").getTable("EMPS"), root); 。原因很好理解:全表扫描的写法是固定的,不需要额外入参,所以可以直接写死用Schemas.enumerable来获取,而谓词下推后的数据查询则每次 SQL 的入参都可能变化,所以要interpreter解释器来执行,这样入参怎么变化都不会影响 EnumerableCalc 的代码生成方式。
总结
SQL 查询引擎的实现本质上是实现 SQL 语言的编译器,Calcite 将 SQL 解析成语法树,然后转成逻辑计划,经过优化器优化之后转成物理计划,最后是生成 Java 代码来执行。这个过程就类似于将 C 语言编译成机器码,GCC 编译器在编译过程中先是将 C 代码进行语法分析生成语法树,然后生成汇编语言,最后进行优化之后才生成机器码。