引言
我已经很久没写过一行代码了。
不是因为懒,而是因为我发现了一件事:当我停止写代码的那一刻,我的产出反而变多了。
这听起来像悖论,但 OpenAI 最近做了一个实验:3 人团队,5 个月,100 万行代码,做法是禁止人类写代码。效率是传统方式的 10 倍。
他们怎么做到的?答案藏在一个叫“Harness 工程”的方法论里。这是一种让 AI 代码不失控的系统性思路,也可以说是 AI 时代的软件工程。
我在春节期间,在自己项目里实践了这套方法。这篇文章会告诉你四件事:Harness 工程到底是什么,OpenAI 具体怎么做的,我怎么用“复利工程”在自己项目里落地,以及 AI 编码时代工程师该扮演什么角色。
什么是 Harness 工程
我最初看到“harness”这个词时,以为只是个测试工具的名字。后来发现它在 AI 领域的用法远比想象中丰富,而且正在经历一场有趣的演变。
在软件工程里,harness 其实是个老词了。Test harness 和 Evaluation harness 用了几十年,指的就是测试和评估的基础设施。EleutherAI 从 2020 年开始做的 Language Model Evaluation Harness 就是这个思路,专门用来测试生成式 AI 模型的表现。
到了 2025 年 11 月,Anthropic 开始用“agent harness”来描述智能体基础设施,直接把 Claude Agent SDK 叫做“a powerful, general-purpose agent harness”。两个月后,HashiCorp 联合创始人 Mitchell Hashimoto 更进一步,把这套实践方法正式命名为“harness engineering”。
Ethan Mollick 在他的 AI 指南里提出了一个更宏观的视角。他把整个 AI 生态拆成三层:Models、Apps、Harnesses。在他看来,harness 指的是让 AI 系统真正发挥作用的那些配套设施,包括工具、记忆、提示词、防护栏等等。
简单来说,模型提供能力,应用提供界面,harness 则负责把能力转化为可控的产出。
我自己关注到 harness 工程是在春节期间,看到 OpenAI 发表的文章:《Harness engineering: leveraging Codex in an agent-first world》,他们尝试让 Codex 构建一个百万行代码库,禁止人写代码,所有代码都是 AI 写的。
agent harness 和 harness engineering
在开始之前,我想先澄清一个容易混淆的概念。刚接触这个领域时,我也曾把 agent harness 和 harness engineering 当成同一回事,后来才发现它们其实是两个层面的东西。
用最直白的话说,agent harness 是一个具体的工具或框架。你可以把它理解为一个“智能体运行环境”,就像 Docker 是容器的运行环境一样。它提供了 agent 运行所需的基础设施,包括工具调用、状态管理、错误处理等能力。
拿 LangChain 的定义来说,agent harness 是一组让长时任务 agent 更容易落地的能力组合。这些能力包括规划、虚拟文件系统、子任务委派、上下文与 token 管理、代码执行、人类介入等。
无独有偶,Anthropic 也用“long-running agent harness“来描述这套外部支撑系统,它负责在 agent 运行过程中保存状态、管理资源、处理异常。
而 harness engineering 在我看来更像是一种工程方法论。它关注的是如何设计和优化整个 agent 系统的架构。这包括如何拆解任务、如何编排多个 agent、如何处理异常情况等。如果用汽车制造来类比,agent harness 是发动机、变速箱这些核心部件,harness engineering 则是整车设计和生产线编排方法。从这个角度讲,Harness 工程更像是传统软件工程的 AI 版本。
OpenAI 对 harness engineering 的理解更进一步。他们描述的是一种 agent-first 的工程方式:不只是让 AI 生成代码,而是把整个开发生命周期都交给 AI 管理。
具体来说,测试、CI、发布工具、内部开发工具、文档与设计历史、评测这些原本分散的环节,全部被纳入同一个可控、可回归的体系里。这意味着当你改了一行代码,相关的测试用例、文档更新、评测都会自动触发,整个流程由 agent 协调完成。
举个具体场景:假设你要做一个客服 agent。agent harness 帮你解决“怎么让 agent 调用知识库 API”这类底层问题,而 harness engineering 则指导你思考“是用单个 agent 还是多个 agent 协作”、“如何设计对话流程”这些架构层面的问题。
刚开始接触这些概念时,我也经常把它们混在一起。后来发现有个实用的判断标准:看你在改“输入”还是在改“生产系统”。
怎么理解?如果你在讨论这轮喂什么信息、怎么摘要、怎么检索,那更偏 context engineering。它本质上是在优化 agent 的输入质量,属于 harness 的一部分。
但如果你在讨论工具权限、CI 门禁、可观测性、回归评测,那就是 harness engineering 的范畴了。这时候你关注的是让 AI 能在整个研发流程里自主跑起来,而不只是单次调用的效果。
理解了这些概念后,我们来看 OpenAI 是怎么把 harness engineering 落地的。
OpenAI 的三个关键实践
OpenAI 是一家非常理想主义的公司,他们的理念是要让 AI 端到端地去完成任务,所以他们花了 5 个月时间做一个非常 AGI 的实验:完全用 AI 去开发一个软件产品。在这个过程中,禁止人类写代码,把所有事情都交给 AI 去完成。
先看几个数字。3 人团队在 5 个月里产出了 100 万行代码和 1500 个 PR,平均每人每天提交 3.5 个 PR。后来团队扩展到 7 人,效率不降反升。最终这个产品有数百名内部用户日常使用,构建时间只有手工编码的十分之一。
这些数字背后,OpenAI 团队其实在解决一个更本质的问题:怎么让 AI 写出的代码不会越来越乱?他们的做法是把确定性方法和大语言模型混合使用,归纳为三个类别:
上下文工程:在代码库里持续积累知识,同时给智能体开放可观测性数据和浏览器导航等动态上下文的访问权限。简单来说,就是让 AI 随时能找到它需要的信息。
架构约束:不只靠 CodeReview Agent 来监控,还配合代码检查工具和自动化测试。这相当于给 AI 设置了一道道门禁,确保代码质量不会失控。
技术债务回收:定期运行智能体,专门去发现文档里的不一致或违反架构约束的地方,然后自动进行重构。这个机制对抗的是代码库的腐化,就像定期打扫房间一样。
OpenAI 团队特别强调了迭代的重要性。当智能体遇到困难时,他们不会直接人工介入修复,而是把这当成信号:找出缺失的工具、约束机制或文档,反馈到代码库里,然后让 Codex 自己来完成修复。
在我看来,上述这些措施的共同点是都在提高长期的内在质量和可维护性。通过牺牲短期的开发速度,让 AI 生成的代码库能够持续演进。
落地指南:复利工程实战
在看到 OpenAI 那篇文章的时候,我有一种“奇点”已经到来的感觉。当我们还在人工地去 review AI 的代码时,OpenAI 已经能够让 AI 自主完成 100 万行代码的开发和维护,并且效率是人类的 10 倍。
用过 AI coding 的人都知道,要让它从零写一个应用是非常简单的。但是真的要让它在生产系统里面自主地完成需求却非常困难,原因就是 AI 没有我们那么多上下文,特别是在一个有很多历史代码的仓库里面。很多上下文其实都在人的脑子里,文档也都过时了。里面有很多历史业务的逻辑,在不断的交接过程中,已经没人知道是从哪里来的。
传统软件工程中,每个新增功能都会让后续开发变得更困难。代码越多,意味着更多边界情况、更复杂的相互依赖关系,以及更难发现的 bug。在 AI 编码时代,这种情况更加普遍。
现在 AI 写代码的速度太快了,而且大部分代码都是 AI 写的,我们已经 review 不过来了。想要让它一层一层地叠上去,做一个复杂功能的时候,就会非常困难。这就像盖楼,地基没打好,越往上叠越危险。
为了让 AI 能够完成复杂任务,我们尝试了很多方法。最常见的是 spec 驱动开发。比如 OpenSpec 这个工具,它把需求从“聊天记录”搬到“可以版本控制的文档”里,包括 proposal、specs、design、tasks 这些。核心目标是:先对齐再开写,降低 agent“凭感觉 coding”的概率。这种方法确实可以让 AI 更加稳定可控地去完成我们的需求。
然而,这种方法存在一个根本性的局限:经验无法沉淀。 每次都是从零开始对齐,上一次踩的坑,下一次还会再踩。
什么是复利工程
相比之下,我更看好 Every 提出的 复利工程(Compound Engineering)。它的核心不是“先写 spec”,而是让每次工程工作都能产生复利效应。具体来说,就是把计划、执行、review 的产出和踩坑经验都记录下来,下一轮就能更快、更稳。Every 的文章把这个循环定义为 Plan → Work → Review → Compound,并强调“80% 的价值在 plan 和 review 这两步”。
如何理解“复利”?传统的 Vibe Coding 追求短期收益:你输入 prompt,AI 生成代码,短平快的从零做一个应用,然后周而复始。而复利工程想做的是一个有记忆的系统。每个 PR 都在教 AI 学东西,每个错误都变成永久经验,每次代码审查都更新默认设置。简单来说,Vibe Coding 让你今天更快,复利工程让你明天更快,而且一天比一天快。
OpenAI 在实践中也提到,他们给 AI 准备了一个知识库,把文档结构化地存进去,方便 AI 理解和使用。但他们只给出了结果,没说具体怎么实现。
这恰好印证了一个核心需求:要让 AI 能够持续迭代,就必须给它配一套知识记录系统。而 Every 的“复利工程”,在我看来正是这个问题的完美解决方案。
上面这些讨论,都是我看完那篇文章后的一些想法。但想法归想法,具体怎么落地还得靠实践。下面我就分享一下,我在“复利工程”和“给 AI 可验证环境”这两件事上的一些经验。
正好我们最近正在重构从零搭建阿福的 Agent 新架构,有了一次从零开始的机会。所以我就在想,能不能在这个应用刚开始的时候,就完全让 AI 去介入,让它像 OpenAI 的实践一样,把所有的上下文和架构规范都落到代码仓库里面。所以我也需要去探索这么一种新的与 AI 协作的方式,也就是 Harness 工程。
为什么选日志可观测性作为切入点
我选了日志的可观测性开发作为切入点。我们新建的这个 Python 应用,日志原来打得不太规范,正好拿它来做一遍重构。同时也能引入 AI,帮我做可观测性规范的约束。
为什么选日志?因为 OpenAI 在文章里提到,他们把日志、指标和追踪数据通过本地可观测性堆栈暴露给 Codex。Codex 能用 LogQL 查日志,用 PromQL 查指标。有了这些上下文,像“确保服务启动在 800 毫秒内完成”或“这四个关键用户旅程中的任何跨度都不超过两秒”这样的提示就好处理了。
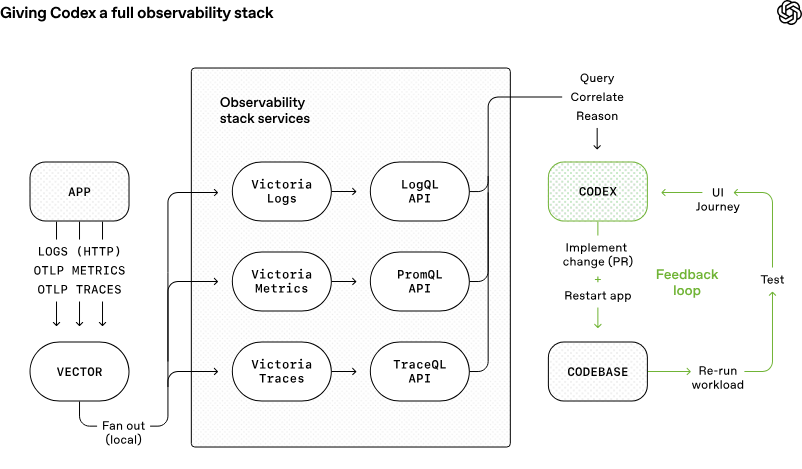
这件事以前很难做,现在有了 AI 就不一样了。 原来我们想做日志规范挺困难的,主要有三个原因:
首先,协作难。这么多人同时写代码,要保证每个人打日志的规范一致,太难了。
其次,插件不够用。虽然能做个代码扫描插件,但扫出问题后还得找人改。
最后,成本高。人工修复成本太高,所以以前大家往往只能口头约定一下,没有强制约束力。
但现在有了 AI,我能把这块工作完全交给它:我定义好规范。AI 帮我写脚本、跑测试、完成修复。
五步闭环:Brainstorm → Plan → Work → Review → Compound
Every 的复利工程推荐流程是:Plan → Work → Review → Compound。但其实我更推荐的是:Brainstorm → Plan → Work → Review → Compound。因为很多时候,我们的需求可能并没有想得那么清楚。在这个过程里,可以让 AI 通过一问一答的方式,帮你把思路理清楚。虽然多这么一步会有点慢,但是把前期的需求提清楚了,后面才能避免返工。
| 命令 | 用途 |
|---|---|
| /workflows: branstorm | 在计划之前,通过协作对话探索需求与方法。 |
| /workflows: plan | 将功能想法转化为详细的实施计划 |
| /workflows: work | 使用工作树和任务跟踪执行计划 |
| /workflows: review | 合并前进行多智能体代码审查 |
| /workflows: compound | 将审查和执行中的经验沉淀为可复用的知识 |
下面分享一下我从零开始,让 AI 给我做这个日志规范的一个过程:
Brainstorm:把模糊想法变成清晰需求
在正式做计划之前,我先踩了个坑:需求本身还没想清楚。当时脑子里只有一个模糊的念头,想给日志系统立个规范,但具体要做到什么程度、用什么方案,没有完全想清楚。
这种情况下直接跳到“怎么做”,大概率会返工。所以我用了 /workflows: brainstorm 这个指令,它的核心作用就是通过一问一答帮你把“要做什么”先理清楚。至于“怎么做”,那是后面 /workflows: plan 的事。
整个流程分四步走。
第一步是评估需求清晰度。如果你的想法已经足够明确,AI 会直接建议你跳到 plan 阶段,不浪费时间。
第二步是理解想法。AI 会先扫一遍现有代码库,找找有没有相关的模式,然后开始有针对性地提问。这个过程很像跟一个经验丰富的同事讨论方案,一次只问一个问题,逐步把你的想法挖出来。
第三步是探索方案。当想法变清晰后,AI 会抛出两三个具体方案,列出各自的优缺点,再给一个推荐。这一步帮你做技术决策,避免拍脑袋。
最后一步是输出文档。AI 会把整个讨论过程和结论整理成结构化文档,存到 docs/brainstorms/YYYY-MM-DD-<topic>-brainstorm.md。这份文档就是后续计划和开发的起点。
我当时的操作是这样的。输入了一句很模糊的指令:
/workflows:branstorm 我想设计一套结构化日志记录、模式与类型的命名规则
AI 先分析了现有代码库,然后开始提问。比如第一个问题是关于覆盖范围的:
先问第一个问题 (一次一个):
你希望这套"命名规范"第一阶段覆盖范围是哪种?
1. 只覆盖日志:日志器名、事件名、字段名、消息模板
2. 日志 + 指标:同时统一 metric 名与 label 键命名
3. 全观测统一:日志 + 指标 + trace/span 语义字段统一
请直接回复 `1` / `2` / `3`。
聊了大概四五轮之后,AI 帮我把模糊的想法提炼成了一份清晰的需求文档:
---
date: 2026-02-16
topic: observability-naming
---
# 全观测 (日志/指标/Trace) 结构化命名规范 Brainstorm
## What We're Building
我们要建立一套覆盖日志、指标、Trace/Span 的统一命名与字段规范,用于全仓库历史日志重构与后续持续治理。该规范将统一事件命名、字段命名、语义字段定义和结果枚举,目标是让检索、排障、跨模块协作和质量治理具备一致语言。
## Why This Approach
候选方案中,选择 A(双轨规范 + 机器字典主导):文档负责原则、边界与语义解释;机器字典负责事件枚举、字段定义、必填规则和可校验约束。这样可以同时满足"可检索性第一"的目标与"第二阶段加校验器"的治理目标。
## Key Decisions
- 统一范围:覆盖日志 + 指标 + Trace/Span(全观测统一)。
- 目标优先级:可检索性 > 跨团队一致性 > 治理与质量 > 外部对齐。
- 事件命名:`domain.action.result`。
...
## Next Steps
→ `/prompts:workflows-plan`:基于该 brainstorm 进入 HOW 设计,细化为分批改造策略、回归验证方案、校验器分阶段落地方案与验收标准。
这份文档后来成了所有后续工作的基础。它不只记录了“要做什么”,还记录了“为什么这样做”和“考虑过哪些替代方案”。这种把思考过程结构化沉淀下来的做法,正是复利工程的核心价值。
Plan:把需求变成实施计划
/workflows: plan 是脑暴之后的下一步,核心就是回答“怎么做”这个问题。它会把前面探索出来的功能描述,变成一份结构化的实施计划。
这个流程大概分六步走。
第一步是找脑暴文档。AI 会先去 docs/brainstorms/ 里翻一翻,看有没有相关的前置探索。有的话就直接继承里面的决策,不用再重复讨论一遍。
第二步是本地调研。这一步会同时跑两个 agent:一个扫代码库里的现有模式,另一个去 docs/solutions/ 里找历史踩坑经验。
第三步是决定要不要做外部调研。涉及安全、支付、外部 API 这类高风险领域,必须查;否则本地上下文够用就跳过。
第四步是生成计划文档。根据任务复杂度,它支持三档详细程度:MINIMAL 适合简单 bug 或小改动,只需要问题描述加验收标准;MORE 适合大多数功能,会加上技术考量、风险分析、系统影响;A LOT 针对架构级变更,包含分阶段实施方案、完整风险评估和文档计划。
第五步是写入文件,保存路径是 docs/plans/YYYY-MM-DD-<type>-<name>-plan.md。
第六步是选择后续动作:可以继续深化计划,也可以做技术评审,或者直接进入 /workflows: work 开始干活。
我自己用下来是这样的。有了前面的脑暴文档后,我直接让 AI 执行这个工作流。它会自动找到脑暴文档,然后开始调研。
不过这个计划不是一次就能出好的。我和 AI 前后迭代了三轮,每一轮都在前一版基础上往深里挖。
第一轮让它自由发挥。AI 结合我的代码和网上搜到的可观测性最佳实践,整理出一版初稿。
第二轮做深度挖掘。我用了 deepen-plan 这个技能,让它在初版基础上继续调研。第一版深度不够,需要它再往下挖。
第三轮对标业界实践。我让它参考 OpenAI Codex 的文章,把里面关于可观测性的做法融进计划。具体指令是这样写的:https://openai.com/index/harness-engineering/ 结合这篇文章中对于 Agent 开发可观测性的一些实践,继续优化计划。
下面是最终生成的计划文档,我做了些删减:
---
title: feat: CodingAgent 本地观测查询接入
type: feat
status: completed
date: 2026-02-16
---
# feat: CodingAgent 本地观测查询接入
## Overview
基于 `docs/brainstorms/2026-02-16-codingagent-local-observability-autonomous-repair-brainstorm.md`,本计划进一步收敛为"只做查询接入"。
...
## Problem Statement / Motivation
项目已有结构化日志和 observability 工具,但 CodingAgent 缺少统一查询入口。当前排查查询方式分散,不利于后续能力复用。
## Research Consolidation
### Internal References
- `docs/brainstorms/2026-02-16-codingagent-local-observability-autonomous-repair-brainstorm.md`
...
### External References
- https://openai.com/index/harness-engineering
- https://opentelemetry.io/docs/specs/otlp/
...
### Deprecation / Compatibility Check
- 未发现 Vector / Victoria* / OTLP 在 2026-02-16 的阻断级 sunset。
- OTel Zipkin exporter 已 deprecate(2025-12),本计划继续坚持 OTLP 主线路。
...
## Proposed Solution
...
### Implementation Phases
...
Work:把计划变成代码
前面脑暴和计划都搞定了,接下来就是真刀真枪写代码。/workflows: work 干的就是这件事:把计划变成实际的代码和 PR。
整个流程我拆成四个阶段来讲。
Phase 1:快速启动
AI 做的第一件事是读计划文档。有看不懂的地方,它会先问清楚,不会闷头就写。然后它会新建一个 feature 分支,不直接在主分支上动手。最后用 TodoWrite 把计划拆成一条条可执行的任务。
Phase 2:执行
任务列表有了,AI 就开始一个个往下推。每完成一个,它会在计划文档里把对应的方框打勾,从 [ ] 变成 [x]。
这里有个细节:每个任务收尾前,AI 会做一遍「系统级影响检查」。查什么?回调链有没有断、错误有没有正确传播、状态有没有不一致。做完一个逻辑单元就提交一次,避免攒到最后一把梭。
Phase 3:质量检查
代码写完不算完,还得跑测试和 lint。复杂点的变更,可以开几个 reviewer agent 专门审安全、审性能。上线前还要准备好监控方案:日志怎么查、指标看哪些、什么情况触发回滚。
Phase 4:发布
最后一步是提交、推送、创建 PR。如果改了 UI,必须截图上传。PR 描述里要写清楚:改了什么、怎么测的、截图在哪、上线后怎么监控。
实际跑起来是什么体验?
我自己用的时候,执行完指令后 AI 会先去读之前的计划文档,然后问我:「要不要新建分支?」确认后它就开始动手写代码。
有一点值得说:AI 不会一口气把活全干完,而是分批交付。拿我的日志重构项目举例,第一轮它只完成了 Phase 1 和 Phase 3 的基础能力,产出了这些东西:
-
一份规范文档:
docs/observability/naming-spec.md -
一个机器字典:
docs/observability/naming-catalog.yaml -
四个 Python 脚本:审计、迁移报告、规则校验、断言
-
一份 Agent 可观测性手册
干完后 AI 会主动汇报:哪些做完了、跑了哪些验证命令、卡在哪里。比如它告诉我缺 pytest 环境跑不了测试。然后它给出三个建议,等我拍板:
下一步建议:
-
继续执行 Phase 2,开始全仓日志迁移
-
先提交一版增量 commit,只包含本轮文档和脚本
-
先把测试环境补齐再继续
我回了句「2,优先用 .venv 环境」,它就选了第二个方案,切到虚拟环境继续干活。
完整的重构涉及大量代码,AI 没法一次做完。我的做法是:每完成一个任务就压缩一次上下文,让它始终聚焦在重构这件事上。
这个过程里最关键的一步是什么?告诉 AI 怎么本地启动服务、怎么验证结果。 我把调试命令和日志路径发给它:
本地启动:s_test install --module_paths file:$(pwd) --skip_pull_dep
跑测试:sh ./src/arec2_py_med_main_agent/test_script/test_stream.sh
日志路径:../arecpyruntimeiiaq/logs/arec2_py_med_main_agent/default.log
有了这些信息,AI 就能自己跑服务、看日志、发现问题、修复问题。这就形成了一个完整的开发闭环。OpenAI 的做法也是这样:让 AI 能独立验证,不依赖人工检查。从这一刻起,我只需要指方向,执行的事情 AI 自己搞定。
Review:多 Agent 并行审查
AI 写代码有个明显的好处:量大、速度快。
但问题也跟着来了。这么多代码谁来 review?如果还是人盯着看,人反而成了瓶颈。
为了解决这个问题,复利工程插件提供了 /workflows: review 指令,就是干这事的。它是一个多 agent 并行审查工具,专门给 PR 做深度质量检查。核心思路是把一个 PR 同时扔给好几个专业 agent,让它们各自审完后把发现汇总成结构化的 todo 文件。
整个流程分四步走。
第一步是确定审查目标。你可以给它 PR 编号、GitHub URL、分支名,或者直接让它审当前分支。
第二步是并行跑多个专项 reviewer。这些 agent 各有分工:security-sentinel 查安全漏洞,performance-oracle 盯性能,architecture-strategist 审架构,code-simplicity-reviewer 看代码是否简洁,agent-native-reviewer 检查 agent 可访问性,learnings-researcher 匹配历史踩坑经验。涉及数据库迁移的话,还会额外跑 schema-drift-detector 和 data-migration-expert.
第三步是多角度深度分析。它会从开发者、运维、用户、安全团队、业务这五个视角审视变更,同时检查边界条件、并发、资源耗尽这些容易出问题的场景。
第四步是生成结构化 todo 文件。所有发现按优先级分类写入 todos/ 目录:P1 是阻塞合并的问题,像安全漏洞、数据风险;P2 是应该修的,像性能、架构问题;P3 是可选优化。
下面举个例子,看看让它 review 一次 commit 的实际效果。
## ✅ Code Review Complete
**Review Target:** 最新提交 `9d6898a` - `refactor(observability): migrate remaining runtime and config logs`
**Branch:** `xiaokai`
### Findings Summary
- **Total Findings:** 2
- **🔴 CRITICAL (P1):** 0
- **🟡 IMPORTANT (P2):** 2
- **🔵 NICE-TO-HAVE (P3):** 0
### Created Todo Files
- `todos/001-pending-p2-web-search-warning-log-leaks-query-content.md`
问题:`web_search` 失败路径在 `warning` 日志记录原始 `query`,有敏感信息暴露风险。
证据:`src/arec2_py_med_main_agent/configs/answer/tools/web_search/v1.py:265`(及 default/default_old/no_tools 对应位置)
- `todos/002-pending-p2-failure-log-lacks-error-message-context.md`
问题:多处异常日志只记录 `error_type`,缺少可诊断错误摘要,降低线上排障效率。
证据:`src/arec2_py_med_main_agent/configs/answer/tools/calculator/v1.py:132`、`src/arec2_py_med_main_agent/configs/default/tools/web_search/v1.py:138`(及其他同类位置)
....
### Next Steps
1. `ls todos/*-pending-*.md` 查看全部待办。
2. 先处理 `001`(日志敏感字段治理),再处理 `002`(可诊断性补强)。
3. 修复后建议跑一次最小回归 (至少覆盖 web_search/calculator 失败路径日志断言)。
Compound:让经验产生复利
脑暴、计划、开发、审查,前面这四步走完,一个完整的 AI 协作流程就跑通了。但问题来了:如果每次开发都从零开始,上次踩的坑下次还得再踩一遍。复利工程真正有价值的地方,其实就在最后这一步:把过程中学到的东西沉淀下来。
/workflows: compound 就是干这事的。说白了,它是一个知识沉淀工具,专门在你解决完问题后,帮你把方案写成文档。为什么叫“复利”?因为第一次解决一个问题可能要花 30 分钟,记下来之后,下次遇到 2 分钟就搞定了。
这个工具设计得很灵活,不是非得等开发完才能跑。几种典型场景:
刚解决完一个问题的时候最适合用,趁上下文还热乎。你随口说一句“搞定了”、“修好了”、“问题解决了”,它会自动触发。当然,手动敲 /workflows: compound 也行。
整个流程分三步。
第一步是并行研究。它会同时派出 5 个 subagent:一个分析问题类型和症状,一个提取根因和解决方案,一个去翻有没有相关的旧文档,一个制定预防策略,还有一个负责给文档分类、起文件名。
第二步是组装写入。等这 5 个 agent 都干完活,主 agent 把结果拼成一份完整的 markdown,写到 docs/solutions/[category]/[filename].md 这个路径下。
第三步是可选增强。根据问题类型,它会自动找对应的专家 agent 来审一遍文档质量。比如性能问题找 performance-oracle,安全问题找 security-sentinel。
最后沉淀下来的文档会记录这些东西:具体报错信息和现象、试过但没用的方法、根本原因分析、能复现的解决步骤和代码示例、怎么预防下次再出问题。
关键在于这些经验怎么被复用。整个工作流是这样闭环的:work 干完、review 过了、PR 合进去,然后用 compound 把这次的经验沉淀下来。下次跑 plan 或者 work 的时候,learnings-researcher 会自动去 docs/solutions/ 里翻历史经验。
举个我自己遇到的例子。有一次开发时发现 Python 打日志会丢 trace_id,原因是跨线程时上下文没传过去。修完之后,我让它把这个坑记下来:
---
module: aq_agent
date: 2026-02-17
problem_type: integration_issue
component: observability
symptoms:
- "同一请求中,入口日志有 trace_id,但中间日志大量显示 '-'"
- "主链路跨 ThreadPoolExecutor / run_in_executor / create_task 后,trace context 丢失"
root_cause: context_propagation_gap
resolution_type: code_fix
severity: high
tags: [observability, trace-context, contextvars, threadpool, asyncio, otel]
---
这份记录的价值很快就体现出来了。两天后我要重构日志格式,把 JSON 改成可读的单行。跑 plan 的时候,它自动召回了这个经验:
---
title: refactor: 可读单行日志与结构化查询对齐
type: refactor
status: completed
date: 2026-02-19
---
## Overview
将模块默认日志从"前缀 + JSON payload"改为"纯可读单行",并保持 VictoriaLogs 侧结构化查询能力不退化。
...
### Institutional Learnings
1. `docs/solutions/integration-issues/trace-context-loss-across-async-thread-boundaries-20260217.md`
- 关键结论:上下文透传不能被格式变更破坏,trace_id/span_id/request_id 一致性是硬约束。
...
AI 在做新计划的时候,主动引用了之前踩的坑,避免了日志重构时再次破坏 trace context 的传递。这就是复利的意思:第一次花 30 分钟解决的问题,变成了后面所有相关开发的安全网。
Harness 工程与复利工程的关系
OpenAI 在 Harness 工程的文章里提到一个做法:给 AI 配一个结构化的知识库。架构文档、设计文档、产品规格、执行计划、参考资料,全都塞进 docs/ 目录,让 AI 随时能翻到需要的信息。
AGENTS.md
ARCHITECTURE.md
docs/
├── design-docs/
│ ├── index.md
│ ├── core-beliefs.md
│ └── ...
├── exec-plans/
│ ├── active/
│ ├── completed/
│ └── tech-debt-tracker.md
├── generated/
│ └── db-schema.md
├── product-specs/
│ ├── index.md
│ ├── new-user-onboarding.md
│ └── ...
├── references/
│ ├── design-system-reference-llms.txt
│ ├── nixpacks-llms.txt
│ ├── uv-llms.txt
│ └── ...
├── DESIGN.md
├── FRONTEND.md
├── PLANS.md
├── PRODUCT_SENSE.md
├── QUALITY_SCORE.md
├── RELIABILITY.md
└── SECURITY.md
这个目录结构告诉你“应该记什么”,但有个关键问题没说清楚:这些文档怎么在开发过程中持续生成?又怎么保证它们跟代码不脱节?
复利工程刚好补上了这块空白。它不只是定义文档该长什么样,更重要的是给了一套完整的工作流。通过 brainstorm、plan、work、review、compound 这五步循环,每次开发都会自动沉淀出对应的文档。不用专门抽时间补文档,写着写着就有了。
我自己跑了 4 天,积累下来的文档结构就是个很好的例子。这些东西不是事后补写的,而是在解决问题的过程中自然冒出来的。
docs
├── plans
│ ├── 2026-02-18-feat-langfuse-local-observability-integration-plan.md
│ ├── 2026-02-16-feat-observability-structured-naming-governance-plan.md
│ ├── 2026-02-19-refactor-readable-logline-structured-query-plan.md
│ ├── 2026-02-19-fix-sofa-traceid-thread-observability-alignment-plan.md
│ ├── 2026-02-16-feat-codingagent-autonomous-observability-repair-loop-plan.md
│ ├── 2026-02-17-refactor-repository-log-instrumentation-remediation-plan.md
│ ├── 2026-02-17-fix-aq-agent-trace-context-propagation-plan.md
│ └── 2026-02-17-feat-observability-signal-boundary-governance-plan.md
├── brainstorms
│ ├── 2026-02-18-vector-msg-field-enhancement-brainstorm.md
│ ├── 2026-02-17-observability-signal-boundary-brainstorm.md
│ ├── 2026-02-25-python-logging-ecosystem-best-practices-brainstorm.md
│ ├── 2026-02-16-observability-naming-brainstorm.md
│ └── 2026-02-19-readable-logline-observability-brainstorm.md
├── solutions
│ ├── integration-issues
│ │ ├── readable-logline-vector-contract-drift-and-alignment-20260219.md
│ │ ├── sofa-traceid-requestid-thread-log-alignment-20260219.md
│ │ └── trace-context-loss-across-async-thread-boundaries-20260217.md
│ ├── best-practices
│ │ ├── unstructured-high-noise-logging-system-20260216.md
│ │ ├── observability-signal-boundary-and-local-dod-governance-20260217.md
│ │ └── agent-execution-duration-metric-empty-without-agent-node-20260218.md
│ └── developer-experience
│ └── error-type-only-logs-missing-error-message-20260216.md
└── observability
├── agent-observability-playbook.md
├── migration-map.generated.md
├── logging-remediation-backlog-20260217.md
├── naming-catalog.yaml
├── migration-map.md
├── audit-report.json
├── naming-spec.md
把两边的目录结构放一起看,互补关系就很明显了。OpenAI 那套侧重于“应该记什么”,比如设计文档、产品规格、架构约束。复利工程这套侧重于“怎么在开发中记”,比如脑暴、计划、解决方案。
这意味着什么?有了这些持续积累的文档,AI 下次再做可观测性相关的功能时,就能直接调用之前踩坑的经验。不用每次都从零开始摸索,省下来的时间是实打实的。
给 AI 一个能自我验证的环境
测试驱动的 AI 编程
《程序员修炼之道》的作者查德·福勒最近写了篇文章,聊到了测试驱动 AI 编程这件事。
你编写测试用例,由 LLM 生成实现代码。测试不通过,代码不发布。 这是一种由不同作者实现代码的测试驱动开发模式。我在 1999 年学到的开发纪律,恰恰是让 AI 辅助开发得以奏效的关键。严谨性从代码由谁编写转移到代码必须满足的条件。测试并不关心实现代码的是人类还是机器,只关注其行为是否正确。 其模式是:内部概率化,边缘确定性。 工程师的职责从编写代码转变为明确意图与验证结果。
怎么理解这段话?我自己的体会是:当 AI 写的代码越来越多,人根本跟不上。我试过让 AI 一口气改十几个文件,改完根本没精力一行行看。这时候最核心的一点,就是给 AI 一套可验证的环境,让测试用例来替你把关。
有了这套环境,AI 就能自己跑测试、自己验功能。我们也得慢慢接受一个现实:以后 AI 写的软件,没法像从前那样追求百分百确定性。
这就像训练大模型。你喂进去一堆数据样本,最后靠评测来判断模型好不好。AI 写的软件也一样,测试做得越扎实,软件质量就越高。人工 review 那套,慢慢会变成辅助手段。
这里说的测试,是广义的测试,不只是单元测试或集成测试,甚至可能都不是代码。
举个真实的例子。OpenAI 怎么让 AI 自己测前端页面?做法特别简单:告诉 AI 要完成哪些功能,给它开一个 Chrome 浏览器,让它自己去点按钮、看结果。整个过程不需要人盯着。
所以核心就一句话:给 AI 一套能拿到反馈的环境。这个环境包括测试,也包括日志、指标这些能告诉它“做对没有”的信息。从这个角度看,AI 写的软件更像是一个概率性的东西,我们得学着把它当黑盒来对待。
工程师的新角色:从写代码到带队友
思科总裁最近在一次访谈里聊到一件事:OpenAI 的一位工程师跟思科团队说,别再把 Codex 当工具用了,要把它当成团队成员。这句话背后的意思是:从“一问一答”变成“一起干活”。
怎么理解这两种模式的区别?
把 AI 当工具的时候,你跟它说的都是“帮我写个函数”、“这里改一下”。上下文被切成一段一段的,AI 只能局部优化,最后串起来的活还是你自己干。
但如果你把它当队友,输入方式会自然变掉。你会告诉它背景是什么、有哪些约束、验收标准怎么定、风险点在哪、测试怎么做。思科的做法是让 AI 先写 plan 文档,然后自己照着执行。这样 review 团队看代码的时候,也能看懂 AI 是怎么想的。说白了,这种“可审计的过程产物”就是把 AI 拉进了团队协作的流程里。
要实现这种协作,最关键的一步是给 AI 一个能自己验证的环境。写代码这件事,大家现在已经习惯交给 AI 了。但测试、验证、上线发布呢?这些也应该让 AI 自己跑通。我前面做的可观测性实验,就是在尝试这件事。
现在最大的卡点在基础设施。线上发布平台、CI/CD 流程、日志排查这些东西,当初都是给人设计的。AI 一旦离开我的电脑,就没法独立验证这些环节,得我帮它把流程串起来。这也是为什么我们今年已经在跟中间件团队合作,要把这些能力开放出来。往远了看,研发基础设施得为 AI 重新设计一遍。
从哪里开始
前面聊了这么多,说点能直接上手的。
1. 从一个小项目开始
找一个有技术债的项目练手,日志规范、代码重构都行。用复利工程的五步闭环跑一遍,不用追求完美,先把循环建起来再说。我们与 AI 的协作,真的就跟带实习生是一样的。你必须要跟它互动,慢慢建立默契,不能光看不做。
2. 把调试命令告诉 AI
这是我觉得最重要的一件事。
我在日志重构项目里有个关键突破,就是把这些信息发给了 AI:
本地启动:s_test install --module_paths file:$(pwd) --skip_pull_dep
跑测试:sh ./src/arec2_py_med_main_agent/test_script/test_stream.sh
日志路径:../arecpyruntimeiiaq/logs/arec2_py_med_main_agent/default.log
有了这三样东西,AI 就能自己跑服务、看日志、发现问题、修复问题。整个开发闭环就通了。本地启动命令、测试脚本、日志路径,这三个信息让 AI 能自己验证结果,不用你一直盯着。
3. 给 AI 建知识库
使用复合工程的开发插件,利用 brainstorms/、plans/、solutions/ 这样的目录结构,让每次开发都能沉淀点东西。不用等项目结束再补文档,解决问题的过程中顺手就记下来。第一次花 30 分钟解决的问题,记下来后下次 2 分钟就能搞定。
现在基础设施还没完全到位,但不妨碍你在自己的项目里先跑起来。等 CI/CD、发布平台都为 AI 重新设计一遍的时候,你已经攒够经验了。
回到开头那个问题:不写代码的工程师,到底在做什么?
答案是:他们在带 AI 队友,而不再敲键盘。他们在设计验证环境,而不再人肉 review。他们在沉淀知识,而不再重复踩坑。
写代码这件事,AI 已经比你快了。但定义“什么代码值得写”,这件事,只有你能做。
这才是 AI 时代工程师真正的护城河。