前言
在上篇文章《从零实现 vLLM (1.2):如何实现张量并行》中,我们深入到 Qwen3DecoderLayer 的第一个核心组件:Qwen3Attention,重点分析 QKVParallelLinear 和 RowParallelLinear,了解了张量并行的原理。今天我们深入到 Attention 组件,学习 FlashAttention 是如何加速 Attention 计算的。
Attention 的计算过程
自注意力的核心计算可以简化为以下公式:
O=softmax(QKT)V O = \text{softmax}(QK^{T})V \\
其中,Q, K, V 分别是查询、键和值矩阵。
标准实现方法
传统的计算方法通常分三步走:
- 第一步: 计算 Logits 矩阵 X=QKTX = QK^{T}
- 第二步: 对 X 按行进行 Softmax 运算,得到注意力得分矩阵 A=softmax(X)A = \text{softmax}(X)。
- 第三步: 用 A 加权 V,得到最终输出 O=AVO = AV。
图书馆例子
上面的公式比较抽象,我们用一个例子来类比一下,假设你是一个图书馆管理员,正在整理一大堆关于不同主题的书籍。
我们有三个核心要素:
- Q (Query - 查询): 你手中的一张清单,列出了你现在特别感兴趣的“主题”关键词。比如,“科幻小说”,“历史事件”,“烹饪食谱”。
- K (Key - 键): 每一本书的“标签”或者“关键词”,用来描述这本书的内容。比如,一本《沙丘》的书有“科幻”、“沙漠”、“史诗”等标签。
- V (Value - 值): 每一本书的“内容摘要”或者“实际内容”。比如,《沙丘》的 V 就是它的故事梗概或文字本身。
现在,我们来看如何完成 Attention 的计算:
第一步:计算 Logits 矩阵 X=QKTX = QK^{T} (寻找匹配度)
这一步的目标是:你的每一个“查询主题”,和每一本书的“标签”,到底有多匹配?
我们把你的“查询主题”和所有书的“标签”进行一一比对,计算它们之间的“相似度”或“相关性”。数学上,这通常通过点积(Dot Product)来完成,点积越大,代表相似度越高。
举例:
你的查询 Q: ” 科幻小说 ”
-
书 1 的标签 K: ” 科幻 ” ” 冒险 ”
-
书 2 的标签 K: ” 历史 ” ” 战争 ”
-
书 3 的标签 K: ” 科幻 ” ” 爱情 ”
当你用“科幻小说”去和书 1 的“科幻”比对时,匹配度很高;和书 2 的“历史”比对时,匹配度很低。
结果: 我们会得到一个“匹配度矩阵”X。每一行代表一个查询,每一列代表一本书。X 里的每个数字就是某个查询和某本书标签的匹配度分数。

第二步:对 X 按行进行 Softmax 运算,得到注意力得分矩阵 A = \text{softmax}(X) (分配注意力)
这一步的目标是:根据匹配度,为每个“查询主题”分配对每本书的“注意力权重”。
Softmax 函数会把所有的匹配度分数转换成 0 到 1 之间的概率值,并且所有概率值加起来等于 1。这意味着对于你的一个查询,它会告诉你应该“多大程度”地关注哪本书。分数越高,注意力权重越大。
举例:
你的查询 Q: ” 科幻小说 ”
- 匹配度分数 X: 书 1 (10 分), 书 2 (0 分), 书 3 (8 分)
经过 Softmax 后:
-
书 1 可能得到 81% 的注意力权重(因为匹配度很高)
-
书 2 可能得到 1% 的注意力权重(几乎不相关)
-
书 3 可能得到 18% 的注意力权重(有一定相关性)
结果: 我们得到一个“注意力矩阵”A。每一行仍然代表一个查询,每一列代表一本书,但里面的数字现在是 0 到 1 之间的权重。

第三步:用 A 加权 V,得到最终输出 O = AV (加权融合内容)
这一步的目标是:根据分配的注意力,将每本书的“内容”进行加权,融合成一个与你的“查询主题”最相关的“综合结果”。
你现在有了每本书的“实际内容”(V 矩阵),以及每个查询对每本书的“注意力权重”(A 矩阵)。你将用这些权重,把相关的书的内容“抽取”出来,并根据其重要性进行组合。
举例:
你的查询 Q: ” 科幻小说 ”
注意力权重 A: 书 1 (81%), 书 2 (1%), 书 3 (18%)
-
书 1 的内容 V: 关于《沙丘》的摘要
-
书 2 的内容 V: 关于《二战史》的摘要
-
书 3 的内容 V: 关于《三体》的摘要
你最终的输出 O 会是:81 % 的《沙丘》摘要 + 1% 的《二战史》摘要 + 18% 的《三体》摘要。 显然,这个综合结果会非常倾向于《沙丘》和《三体》这类科幻小说,而忽略《二战史》。
结果: 我们得到最终的输出矩阵 O。每一行对应一个查询,其内容是根据该查询的注意力权重,从所有书的 V 中加权平均得出的“综合信息”。

图书馆例子跟实际矩阵计算的联系
前面用了一个图书馆的例子来类比注意力计算的过程,接下来结合真正的矩阵计算来加深理解。
假设我们的输入有 3 个词(或者在我们的例子里是 3 本书),我们想计算第一个词(“科幻小说”查询)对其他所有词的注意力。在真实的 Transformer 模型中,Q、K、V 都是大型矩阵,但为了方便理解,我们先聚焦于计算一行的过程。
第一步:计算匹配度 X = QKᵀ
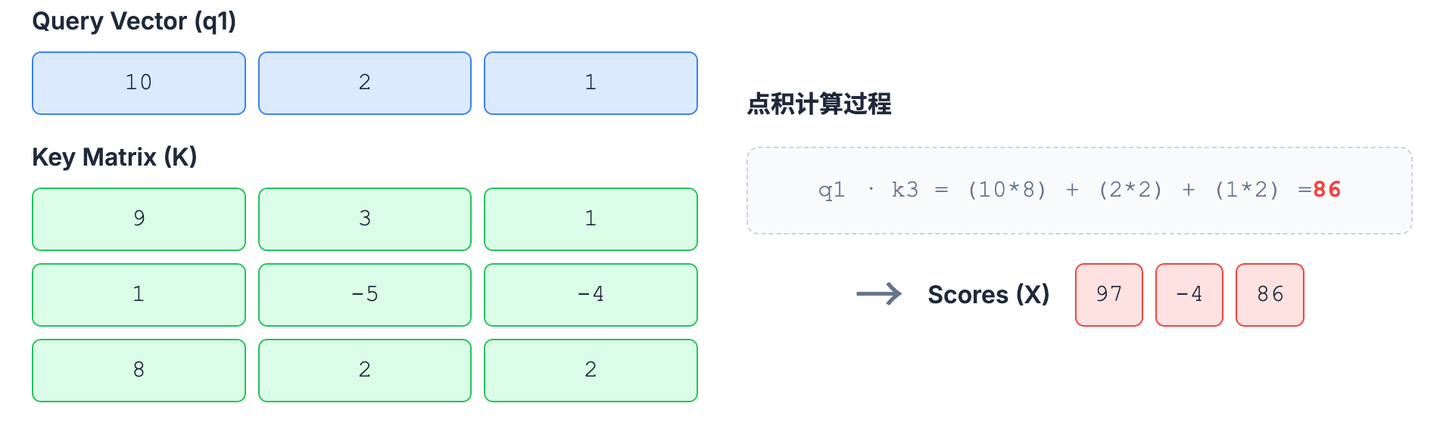
图书馆比喻: 用你的查询 ” 科幻小说 ” (Q),去和每本书的标签 ” 科幻…” (K1), ” 历史…” (K2), ” 科幻…” (K3) 逐个比较,得出匹配分数 [10.0, 0.1, 8.5]。
矩阵计算: 在数学上,这个“比较”操作就是点积 (Dot Product)。点积可以衡量两个向量的相似度。Q (Query): 不再是一个词,而是一个代表 ” 科幻小说 ” 的查询向量。比如 q1 = [10, 2, 1]。 K (Key): 每本书的标签也被转换成了键向量。
k1(书 1: ” 科幻 ”, ” 沙漠 ”, ” 史诗 ”) ->[9, 3, 1](和 q1 很像)k2(书 2: ” 历史 ”, ” 战争 ”) ->[1, -5, -4](和 q1 很不像)k3(书 3: ” 科幻 ”, ” 爱情 ”) ->[8, 2, 2](和 q1 比较像) 计算: 我们用q1去和每一个k做点积:q1 · k1= (10*9 + 2*3 + 1*1) = 97 (分数很高)q1 · k2= (10*1 + 2*-5 + 1*-4) = -4 (分数很低)q1 · k3= (10*8 + 2*2 + 1*2) = 86 (分数比较高)
这些计算出的分数 [97, -4, 86] 就对应着我们比喻中的 [10.0, 0.1, 8.5](数值不同但意义相同),它们共同组成了匹配度矩阵 X 的一行。
第二步:分配注意力 A = softmax(X)
图书馆比喻: 将原始分数 [10.0, 0.1, 8.5] 转换成百分比 [81%, 1%, 18%],确保它们的总和是 100%。
矩阵计算: 这一步在数学上是完全相同的。Softmax 函数就是用来做这个“归一化”操作的。它接收一行原始分数(Logits),然后输出一组 0 到 1 之间的概率值,且总和为 1。
- 输入: 匹配度分数
[97, -4, 86]。 - Softmax 操作: 对这个向量应用 Softmax 函数。它会通过指数运算放大差距,使得高分更接近 1,低分更接近 0。
- 输出: 得到注意力权重矩阵 A 的一行,比如
[0.81, 0.01, 0.18]。
(在实际计算中,通常会有一个缩放步骤 softmax(QKᵀ / √d_k),用键向量的维度 d_k 的平方根来缩放点积结果,这能让训练过程更稳定,但核心思想不变。)

第三步:加权融合内容 O = AV
图书馆比喻: 用注意力权重 [81%, 1%, 18%],去加权融合三本书的内容摘要 (V)。 最终结果 = 81% * (书1内容) + 1% * (书2内容) + 18% * (书3内容)
矩阵计算: 这在数学上是一个加权求和,可以通过矩阵乘法高效完成。
V (Value): 和 Q, K 一样,每本书的“内容”也被表示成一个值向量。
计算: 将我们上一步得到的注意力权重 A (一行) 与整个 V 矩阵 (多行) 相乘。
o1 = 0.81 * v1 + 0.01 * v2 + 0.18 * v3
输出: 得到的结果 o1 是一个全新的向量。这个向量就是输出矩阵 O 的第一行,它成功地融合了所有书籍的信息,但高度侧重于与原始查询“科幻小说”最相关的书籍内容。

总结
| 比喻步骤 | 描述 | 矩阵计算 | 目的 |
|---|---|---|---|
| 第一步 | 查询 Q vs 标签 K | X = QKᵀ (点积) | 计算序列中每个词与其他所有词的相似度 |
| 第二步 | 分数 -> 百分比 | A = softmax(X) | 将相似度分数归一化为注意力权重 |
| 第三步 | 按百分比融合内容 V | O = AV (加权求和) | 根据注意力权重,融合所有词的信息,生成新的表达 |
Attention 的计算结果有什么意义?
简单来说,o1 是输入序列中第一个元素(我们用 q1 来查询的那个元素)的一个全新的、融合了上下文信息的表达。
我们可以从两个层面来理解它:
从图书馆的比喻来看:
输入 (Input): 你感兴趣的主题 ” 科幻小说 ”。
输出 (o1): 一个为你“量身打造”的综合摘要。这个摘要 81% 像《沙丘》,18% 像《三体》,只有 1% 像《二战史》。
o1 的意义: 这个新的摘要本身就代表了“科幻小说”,但不再是一个孤立的词,而是根据图书馆里所有相关的书籍内容,被具体化、丰富化了。它现在知道了,在这个图书馆的语境下,“科幻小说”主要和“沙漠史诗”、“宇宙博弈”这些概念相关。
从矩阵计算和 NLP 的角度来看:
输入 (Input): 假设我们的输入是一句话 “The cat sat on the mat”。第一个词是 “The”,它的向量最初只代表 “The” 本身。我们用 q1 来代表 “The” 发出查询。
输出 (o1): o1 是 “The” 这个词的新向量。这个新向量是通过加权融合句子中所有词的 V 向量得到的。如果计算出的注意力权重让 “The” 高度关注 “cat”,那么 o1 就会包含很多来自 “cat” 的信息。如果 “The” 也关注了 “mat”,那么 o1 也会包含一些来自 “mat” 的信息。
o1 的核心价值:上下文感知 (Context-Awareness)
这是最重要的一点。原始的输入向量是“上下文无关”的。例如,在 “river bank”(河岸)和 “investment bank”(投资银行)中,“bank” 这个词的初始输入向量是完全一样的。
但是,经过 Self-Attention 计算后:
- 在 “river bank” 中,“bank” 的输出向量
o会因为它高度关注了 “river” 而吸收 ” 河流 ” 的信息。 - 在 “investment bank” 中,“bank” 的输出向量
o会因为它高度关注了 “investment” 而吸收 ” 金融 ” 的信息。
因此,即使输入相同,输出的 o 向量也完全不同。它们不再是孤立的词,而是携带了整句话上下文意义的、经过重新编码的表达。这个全新的、信息量更丰富的向量 o 会被传递给神经网络的下一层进行处理。
总结一下:
o1 就是原始输入的“升级版”。 它通过 Self-Attention 机制审视了序列中的所有其他元素,并根据相关性大小,有选择地将它们的信息融入自身,最终形成一个对当前任务更有用、更能体现上下文关系的新表达。
如何加速 Attention 计算
Attention 的代码比较简单,因为它底层的计算都是直接调用了 FlashAttention 的库,所以我们先了解一下 FlashAttention 的原理,为理解源码做好铺垫。
FlashAttention 的核心创新在于,它借鉴了在线 Softmax(Online Softmax)的思想,通过一种“分块(Tiling)”的计算方法,将整个自注意力(Self-Attention)的计算过程融合在一个单一的 CUDA 核心(Kernel)中执行。这样做最大的好处是避免了将中间计算结果,即 Softmax 的 Logits 矩阵 (X) 和注意力得分矩阵 (A),写入速度较慢的 GPU 全局内存(Global Memory)中,从而显著提升了计算效率和内存使用效率。下面我们详细展开一下。
自注意力机制的核心挑战
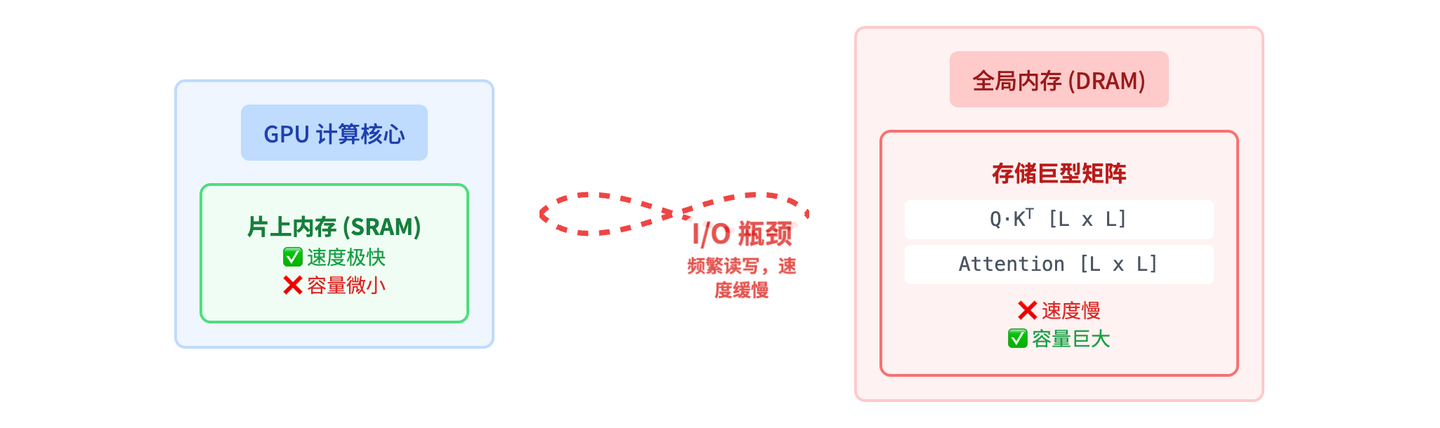
I/O 瓶颈
在标准方法中,矩阵 X 和 A 需要被完整地计算出来并存储在 GPU 的全局内存中。对于很长的序列(L 很大时),这两个矩阵会占用巨大的内存空间,并且频繁地读写全局内存会造成严重的性能瓶颈,因为 GPU 的片上内存(SRAM/Shared Memory)虽然快但很小,而全局内存(DRAM)虽然大但慢得多。
这个可以类比 CPU 的 为 CPU 访问主内存(RAM)和 CPU 缓存(Cache)之间的性能差异。GPU 的全局内存(DRAM)类似于 CPU 的主内存(RAM):它们容量大但访问速度相对较慢。GPU 的片上内存(SRAM/Shared Memory)类似于 CPU 的 L1、L2、L3 缓存:它们容量小但访问速度非常快。
当 CPU 需要处理的数据量很大,无法完全放入高速缓存时,CPU 就需要频繁地从较慢的主内存中读取数据,这会成为一个严重的性能瓶颈,就像 GPU 频繁读写全局内存一样。
不可直接分块
像矩阵乘法这样的运算,由于加法满足结合律,可以很自然地被分解成对小块矩阵的运算,然后将结果累加。但 Softmax 运算中包含了求和与指数运算,它本身不满足结合律,导致自注意力机制无法像矩阵乘法进行分块处理。

“安全 Softmax”的提出
Softmax 还存在一个数值溢出问题:
Softmax 的计算公式为 \frac{e^{x_i}}{\sum_j e^{x_j}}。当 x_i 的值较大时,e^{x_i} 很容易超出浮点数的表示范围(例如,float16 类型在 x \ge 11 时就会溢出),导致计算错误。
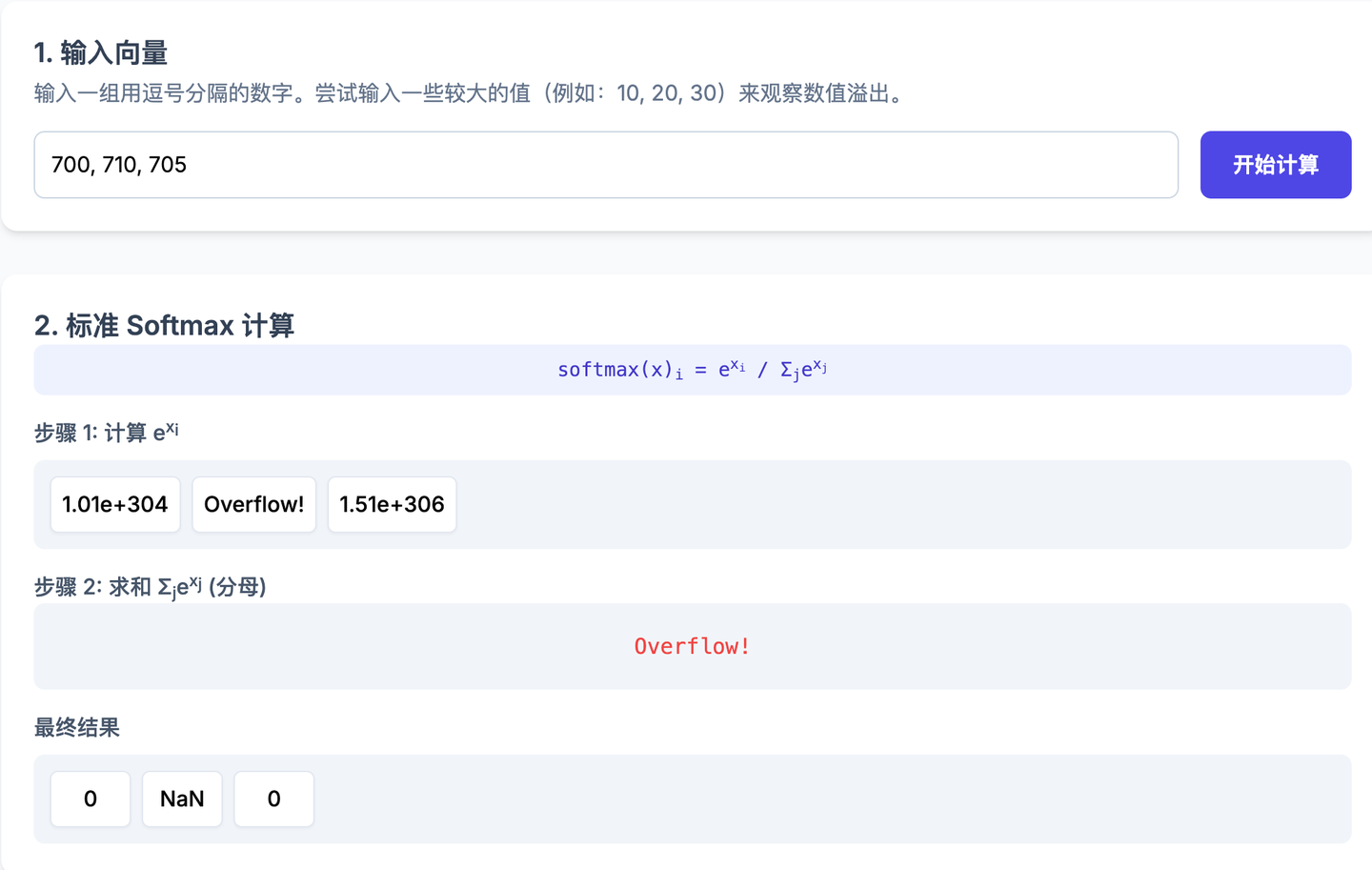
比如 700, 710, 705 三个数去算 softmax 就会 Overflow。
解决方法
为了保证数值稳定性,实际计算中会使用一种叫做“安全 Softmax”的技巧。方法是从输入向量的每个元素中减去该向量的最大值 m:
\text{softmax}(x)_i = \frac{e^{x_i - m}}{\sum_j e^{x_j - m}} \quad \text{其中} \; m = \max_j(x_j) \\
这样做可以保证指数函数的输入都是非正数,从而避免了上溢问题。
实现安全 Softmax 需要对数据进行三次遍历(3-Pass):
- 第一次遍历:找到所有输入值中的最大值 m_N。
- 第二次遍历:使用这个最大值 m_N 计算分母 d_N = \sum_j e^{x_j - m_N}。
- 第三次遍历:计算每个最终的 Softmax 值 a_i = \frac{e^{x_i - m_N}}{d_N}。
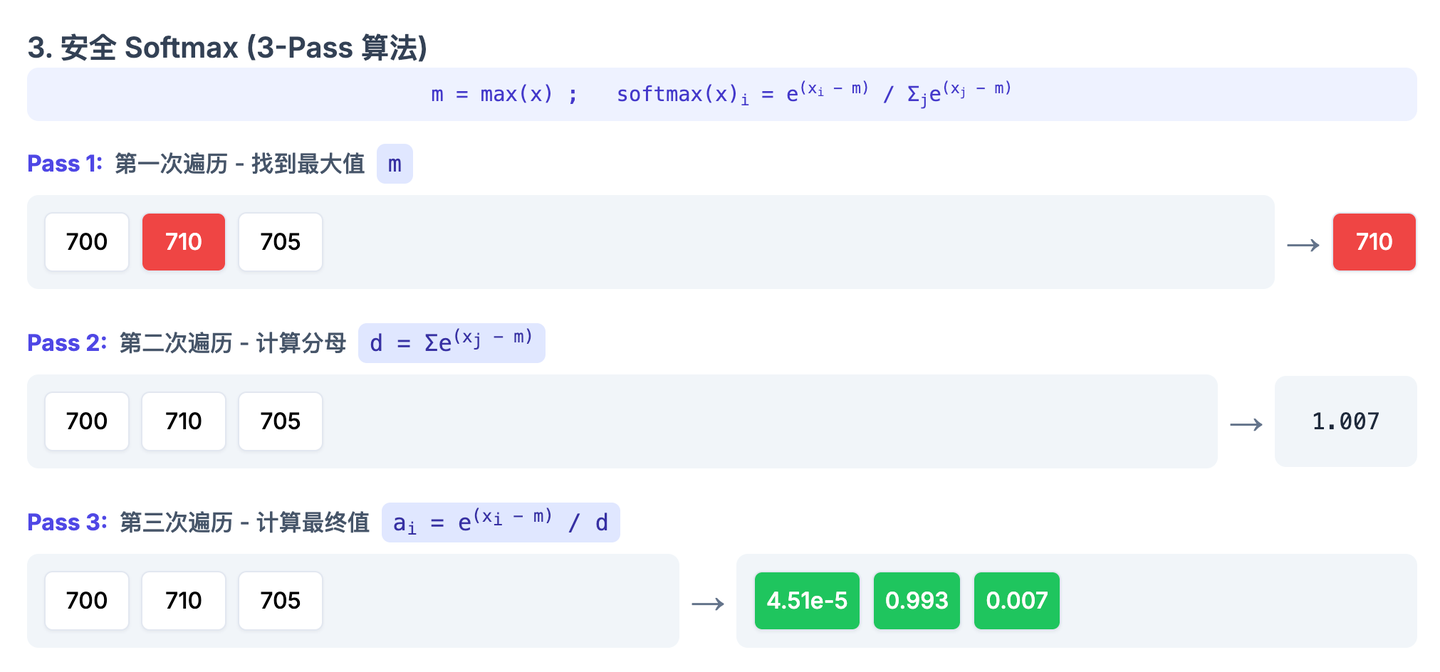
从上面的图可以看到,改成三次遍历计算后就不会 overflow 了。
但是这也带来一个问题,在注意力计算中,这意味着要对 Q 和 K 矩阵进行三次访问(或重复计算)来得到 Logits,I/O 效率极低。
减少遍历次数的“在线 Softmax”
为了减少对全局内存的访问次数,研究者提出了在线 Softmax,可以将 3 次遍历减少到 2 次。
核心技巧:“代理”序列与递推关系
直接合并前两次遍历是困难的,因为计算分母依赖于全局最大值 m_{N}。
在线 Softmax 引入了一个“代理”序列 d_{i′},它使用截至当前的最大值 m_{i} 来计算:
d_{i′}=\sum_{j=1}^{i} e^{x_{j}−m_{i}}其中 m_{i}=\max_{j=1}^{i} \left(x_{j}\right) \\
通过推导,d_{i′} 和 d_{i−1′} 之间存在一个递推关系:
d_{i′}=d_{i−1′}e^{m_{i−1}−m_{i}}+e^{x_{i}−m_{i}} \\
这个递推关系非常关键,因为它可以让我们在一次遍历中同时更新当前的最大值 m_{i} 和当前的代理分母 d_{i′}。
计算流程(2-Pass 算法)
- 第一次遍历:从头到尾扫描数据,利用递推公式计算并保存所有的 m_{i} 和 d_{i′}。
- 第二次遍历:使用第一次遍历得到的最终值 m_{N} 和 d_{N′},再次遍历数据计算出最终的 Softmax 得分 a_{i}。
上面的公式比较抽象,下面我们举个具体例子看看计算的过程,假设我们要计算输入数据:[10, 0, 8, 12, 5] 的 softmax,计算过程如下所示:

2-Pass 虽然比 3-Pass 好,但仍然需要两次数据访问,并不是最优解法。
FlashAttention 的最终实现
FlashAttention 的作者意识到,虽然我们无法在一次遍历中得到最终的注意力得分矩阵 A,但我们的最终目标是输出矩阵 O=AV。那么,是否可以在一次遍历中直接算出 O 呢?答案是肯定的。
核心技巧:对输出 O 应用在线思想
再次使用了“代理”序列的技巧,这次是为输出向量 o 定义一个代理 o_{i′}:
o_{i′}=\sum_{j=1}^{i} \frac{e^{x_{j}−m_{i}}}{d_{i′}}V\left[j,:\right] \\
其中 m_{i} 和 d_{i′} 是在线 Softmax 中计算的截至当前的最大值和代理分母。
通过一系列巧妙的数学推导,可以得到 o_{i′} 与 o_{i−1′} 之间的递推关系:
o_{i′}=o_{i−1′}\frac{d_{i−1′}e^{m_{i−1}−m_{i}}}{d_{i′}}+\frac{e^{x_{i}−m_{i}}}{d_{i′}}V\left[i,:\right] \\
这个公式是 FlashAttention 的核心。它表明,我们可以仅利用上一步(i-1)和当前步(i)的信息,就能计算出当前的代理输出 o_{i′}。
计算流程(1-Pass 算法与分块)
单次遍历(One-Pass):有了上述递推公式,我们就可以在一次循环中,同时计算和更新 m_{i},d_{i′},o_{i′} 这三个状态。
分块(Tiling):由于上述更新操作都满足结合律,这个算法可以很好地与分块思想结合。具体做法是:
- 将 K 和 V 矩阵沿序列长度维度切分成多个块(Tiles)。
- 依次将 Q 的一行、K 和 V 的一个块加载到高速的片上 SRAM 中。
- 在 SRAM 中完成对这个块的计算,并更新全局的 m,d^{′},o^{′} 状态。
- 处理下一个块,直到所有块都计算完毕。
上面的算法同样比较抽象,下面我们举一个具体的例子方便理解。
假设我们要计算向量 [1,2] 的 Attention。
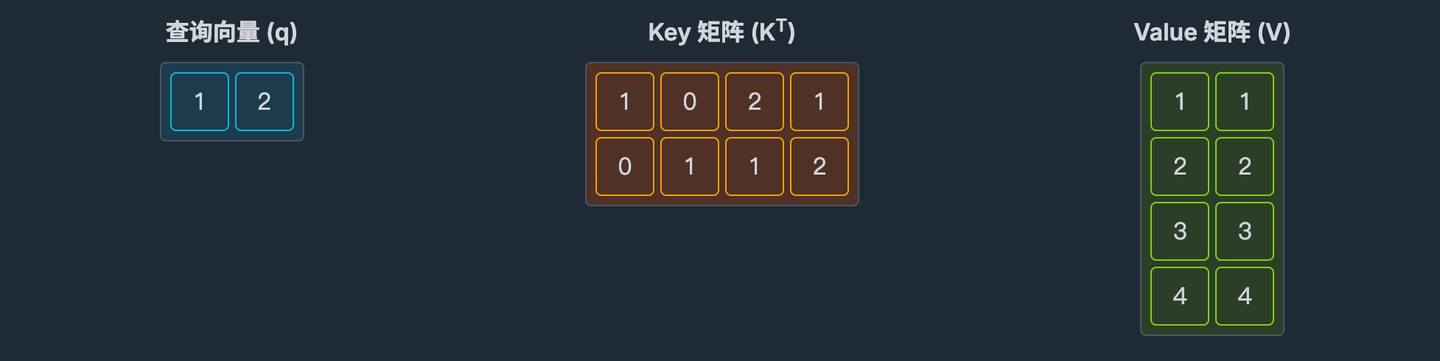
这里需要初始化三个全局变量。

首先我们要对 KV 矩阵进行分块,将 K 和 V 矩阵沿序列长度方向分成 2 个块 (b=2)。

接下来计算第一个块的结果。
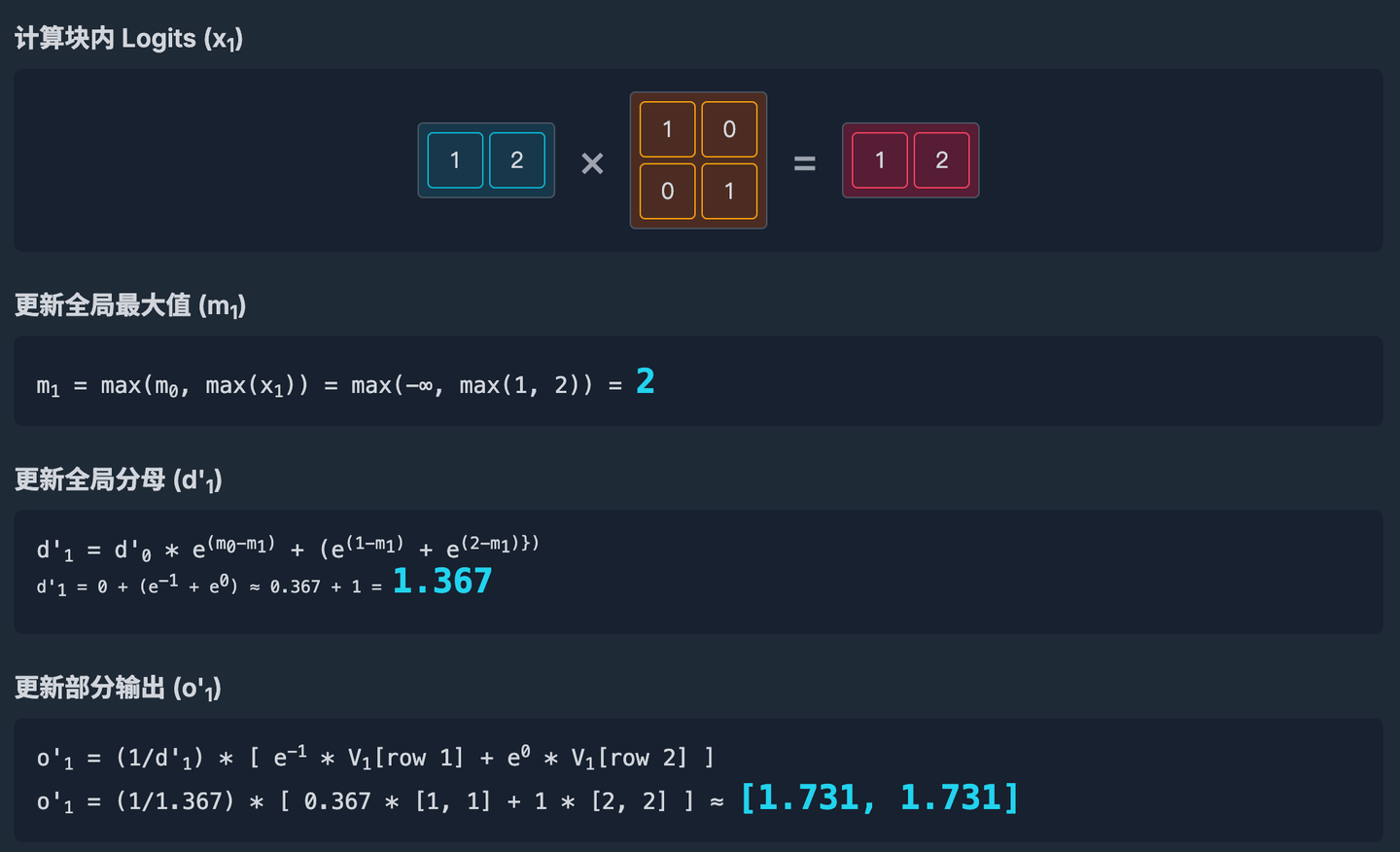
然后是计算第二个块的结果。
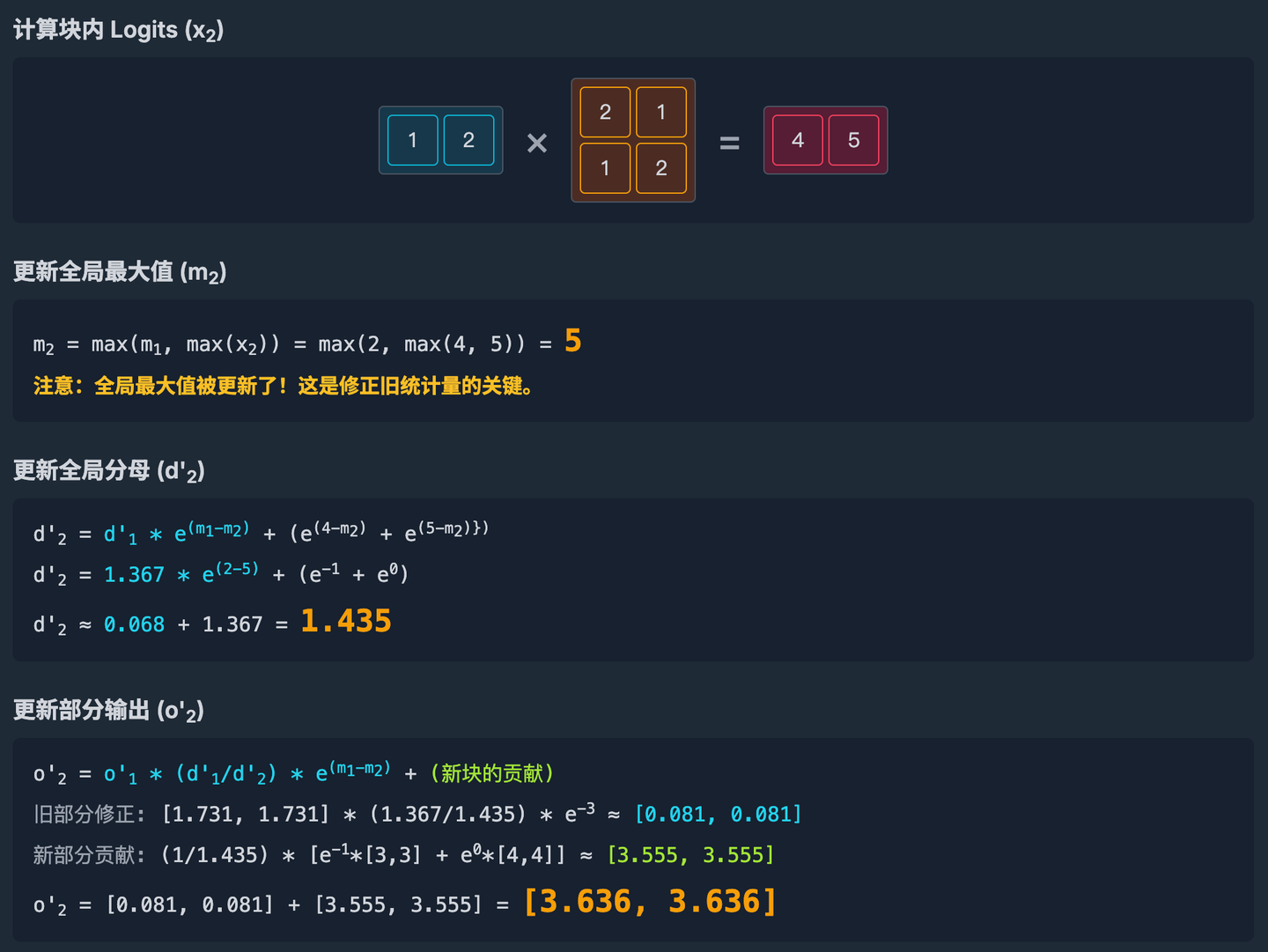
所有块都已处理完毕。我们得到了与标准 Softmax 一致的结果,但全程没有在内存中构建一个完整的 4x4 注意力分数矩阵。通过迭代更新 m, d’, o’ 这三个“全局统计量”,我们在极小的 SRAM 空间中完成了计算。
通过这种在线更新和分块的策略,FlashAttention 实现了在单次遍历内核中完成整个注意力计算。主要有三个提升点:
- I/O 感知:它大大减少了对慢速 GPU 全局内存的读写次数,避免了操作巨大的中间矩阵 A 和 X。
- 内存高效:算法在片上 SRAM 中占用的内存只与块大小 B 和头维度 D 有关,与总序列长度 L 无关。这使得它能够处理比标准注意力长得多的序列。
- 速度更快:由于减少了 I/O 瓶颈,它的计算速度比标准实现快很多,尤其是在处理长序列时。
注意上面我们为了方便理解举的是一个 Q 计算的过程,在 FlashAttention 的实际计算过程中,一般都是多个 Q 一起输入进去,然后对每个 Q 都并行跟 KV 进行计算。但对于每个 Q 它需要串行跟 KV 的分块进行计算。

Attention 源码分析
Attention 的代码很简单,因为它底层的计算都是直接调用了 FlashAttention 的库。它主要分为两个过程:Prefill 和 Decode。
def forward(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor):
context = get_context()
k_cache, v_cache = self.k_cache, self.v_cache
if k_cache.numel() and v_cache.numel():
store_kvcache(k, v, k_cache, v_cache, context.slot_mapping)
if context.is_prefill:
if context.block_tables is not None: # prefix cache
k, v = k_cache, v_cache
o = flash_attn_varlen_func(
q,
k,
v,
max_seqlen_q=context.max_seqlen_q,
cu_seqlens_q=context.cu_seqlens_q,
max_seqlen_k=context.max_seqlen_k,
cu_seqlens_k=context.cu_seqlens_k,
softmax_scale=self.scale,
causal=True,
block_table=context.block_tables,
)
else: # decode
o = flash_attn_with_kvcache(
q.unsqueeze(1),
k_cache,
v_cache,
cache_seqlens=context.context_lens,
block_table=context.block_tables,
softmax_scale=self.scale,
causal=True,
)
return o
Prefill
Prefill 主要目的是计算输入序列的完整 Attention 输出,让模型理解用户输入,顺便生成 KVCache,为后续 Decode 阶段提供历史信息。
if k_cache.numel() and v_cache.numel():
store_kvcache(k, v, k_cache, v_cache, context.slot_mapping)这段代码会将当前计算出的 K 和 V 存入 KV Cache。
if k_cache.numel() and v_cache.numel():检查 KV Cache 是否已经被成功分配。store_kvcache(...): 调用一个自定义的 Triton 内核函数。这个函数的作用是根据context.slot_mapping(一个“内存地址”映射表),将当前批次新计算出的k和v张量高效地、非连续地写入到全局的k_cache和v_cache中的指定位置。
if context.is_prefill:
if context.block_tables is not None: # prefix cache
k, v = k_cache, v_cache
o = flash_attn_varlen_func(
q,
k,
v,
max_seqlen_q=context.max_seqlen_q,
cu_seqlens_q=context.cu_seqlens_q,
max_seqlen_k=context.max_seqlen_k,
cu_seqlens_k=context.cu_seqlens_k,
softmax_scale=self.scale,
causal=True,
block_table=context.block_tables,
)接下来进入处理前缀缓存(Prefix Caching)的情况。如果 context.block_tables 存在,说明当前批次中可能包含了已经计算过并缓存了部分前缀的序列。在这种情况下,用于注意力计算的 Key 和 Value 不仅仅是当前新输入的 token 对应的 K/V,而是整个存储在 k_cache 和 v_cache 中的历史 K/V。
这里稍微展开解释一下 block_tables 是什么,它有点像操作系统里面的虚拟内存页表。

假设我们现在有两个序列 A 和 B,它们有一个共同的 system prompt,所以有一部分前缀的 KVCache 是可以共享的,如上图所示,Block 12 是共享的前缀。一个序列的 KVCache 会被切分成一个个块,这样能减少显存碎片化,提升显存使用率。block_tables 会告诉底层的 FlashAttention 内核如何从这片大的缓存中找到每个序列对应的块。
接下来会调用 FlashAttention 为 Prefill 阶段优化的内核。
flash_attn_varlen_func 专门用于处理批次内序列长度不一的情况(variable length)。
causal=True: 启用因果遮罩,确保每个 token 只能关注到它自己及之前位置的 token。block_table: 传入 PagedAttention 的核心数据结构——块表,指导内核如何在非连续的显存中找到正确的 KV 数据块。
这里解释一下 varlen 的作用,传统的 Attention 处理不同长度的 Q 需要做 padding,这样浪费显存。
Q_padded = [
[Q1_tokens + padding], # 5 + 0 = 5
[Q2_tokens + padding], # 2 + 3 = 5 (浪费 3 个位置)
[Q3_tokens + padding], # 1 + 4 = 5 (浪费 4 个位置)
]varlen 的存储方式是只存储有效 token,无 padding,可以节省 padding 的显存。
Q_varlen = [Q1_tokens, Q2_tokens, Q3_tokens]
K_varlen = [K1_tokens, K2_tokens, K3_tokens]通过 cu_seqlens 参数可以知道每个 QKV 的位置,V 的长度跟 K 一样,所以只需要提供 K 的信息。
cu_seqlens_q = [0, 5, 7, 8] 告诉内核:
- 样本 1 的 Q: 从位置 0 到 5 (不包含 5) → q_batch[0:5]
- 样本 2 的 Q: 从位置 5 到 7 (不包含 7) → q_batch[5:7]
- 样本 3 的 Q: 从位置 7 到 8 (不包含 8) → q_batch[7:8]
cu_seqlens_k = [0, 9, 16, 19] 告诉内核:
- 样本 1 的 K: 从位置 0 到 9 → k_batch[0:9]
- 样本 2 的 K: 从位置 9 到 16 → k_batch[9:16]
- 样本 3 的 K: 从位置 16 到 19 → k_batch[16:19]
# 实际在显存中的存储方式:
q_batch = torch.cat([Q1, Q2, Q3], dim=0) # shape: [7, nheads, headdim]
k_batch = torch.cat([K1, K2, K3], dim=0) # shape: [19, nheads, headdim]
v_batch = torch.cat([V1, V2, V3], dim=0) # shape: [19, nheads, headdim]
# FlashAttention 内核的处理逻辑:
for i in range(batch_size):
start_q = cu_seqlens_q[i] # [0, 5, 7]
end_q = cu_seqlens_q[i+1] # [5, 7, 8]
start_k = cu_seqlens_k[i] # [0, 9, 16]
end_k = cu_seqlens_k[i+1] # [9, 16, 19]
# 取出第 i 个样本的数据进行 attention 计算
qi = q_batch[start_q:end_q] # 样本1: [0:5], 样本2: [5:7], 样本3: [7:8]
ki = k_batch[start_k:end_k] # 样本1: [0:9], 样本2: [9:16], 样本3: [16:19]
vi = v_batch[start_k:end_k] # V 与 K 的索引相同下面我们看一个图方便理解,假设现在我们处于前缀缓存 (Prefix Cache) 场景下的 prefill 阶段,此时每个样本的 Q 只包含 ” 新 token”,而 K/V 包含整个上下文。
假设我们现在有 3 个样本同时计算 Attention:
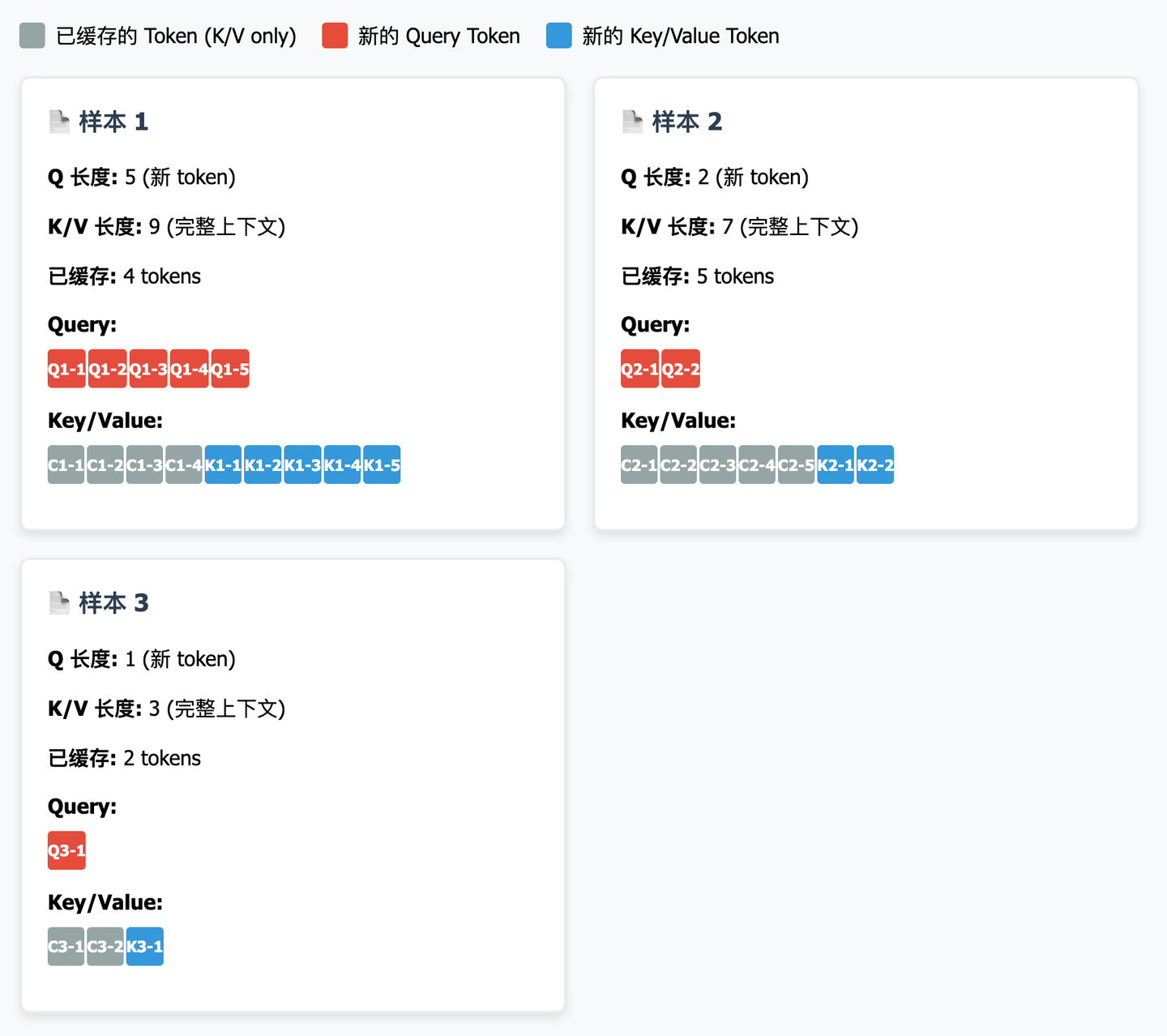
它们在摊平之后会变成这样:

那四个参数就应该是下面这样:

Decode
Decode 阶段是逐个生成 token 的过程:它每次只处理 1 个新生成的 token,这个新 token 需要与所有历史 token 进行 Attention 计算,利用 Prefill 阶段已缓存的 KVCache 避免重复计算。
所以它调用的 Function 是 flash_attn_with_kvcache
o = flash_attn_with_kvcache(
q.unsqueeze(1),
k_cache,
v_cache,
cache_seqlens=context.context_lens,
block_table=context.block_tables,
softmax_scale=self.scale,
causal=True,
)这里解释一下 q.unsqueeze(1) 的作用。
在 decode 阶段,q 的原始形状是:
q.shape = [batch_size, num_heads, head_dim]
# 例如:[2, 32, 128] # 2 个样本,32 个头,每个头 128 维unsqueeze(1) 后的形状
q.unsqueeze(1).shape = [batch_size, 1, num_heads, head_dim]
# 例如:[2, 1, 32, 128] # 在第 1 个位置插入维度 1为什么需要这个操作?因为 flash_attn_with_kvcache 期望的输入格式是:
q: [batch_size, seqlen_q, num_heads, head_dim]
k_cache: [num_blocks, block_size, num_heads, head_dim]
v_cache: [num_blocks, block_size, num_heads, head_dim]维度对应关系
# 标准的 Attention 输入格式
[batch_size, seqlen_q, num_heads, head_dim]
↓ ↓ ↓ ↓
样本数 查询序列长度 注意力头数 每个头的维度
# Decode 时的具体值
[ 2, 1, 32, 128]
↓ ↓ ↓ ↓
2 个样本 1 个新 token 32 个头 128 维总结
当你理解了 FlashAttention 的原理之后,会有一种非常熟悉的感觉。它的巧妙之处,不在于为 AI 提出了什么新的数学公式,而是源于对一个和计算本身一样古老问题的深刻洞见:内存访问很慢。
标准 Attention 的瓶颈,在于它要和 GPU 缓慢的主存(HBM)进行痛苦的、持续的往返通信,这就像 CPU 放着高速缓存不用,而非得去慢速内存里取数据一样。FlashAttention 的核心诀窍,是把 GPU 那块微小而高速的 SRAM 当作一间工作室。它一次性把所需的物料——也就是 Q、K、V 的数据块——搬进工作室,然后在里面完成所有工序:乘法、缩放、合并,自始至终都没有把乱七八糟的半成品搬出去过。
将多个步骤融合成一个 CUDA Kernel,就像把工厂里分散的“钻孔”、“喷漆”、“打磨”三个工位,合并成一个超级工作台。零件不再需要在每个工序后都大费周章地送回中央仓库,而是在同一个地方一气呵成。因为真正拖慢效率的不是加工本身,而是来回运输的成本。
而“在线 Softmax”算法,则像是那种你因为内存装不下一整部电影而设计出的流式处理方案。甚至连保证数值稳定的技巧,也是数值计算教科书里的经典招数。
一个为 Attention 计算带来极大加速的技术,其内核只不过是一场计算机体系结构的大师级实践课。它证明了,最深刻的优化往往不是发明新事物,而是熟练掌握最基本原则,并应用于新的硬件之上。
山川地貌会变,但万有引力定律亘古不变。