前言
在上篇文章《从零实现 vLLM(1.3):如何加速 Attention 计算》中,我们深入分析了 Qwen3Attention 组件,学习了 FlashAttention 如何通过在线 Softmax 和分块计算技术,将 Attention 的计算效率提升到极致。今天这篇文章,我们将目光转向 Transformer 架构中另一个看似简单、却至关重要的组件:RMSNorm(均方根归一化)。
什么是 RMSNorm
RMSNorm(Root Mean Square Normalization)是一种比传统 LayerNorm 更高效的归一化技术,是目前大模型中主流的选择。
在了解 RMSNorm 的原理之前,首先我们要先回答一个问题:归一化是为了解决什么问题?归一化主要是为了解决深度学习中内部协变量偏移问题而提出的。
什么是内部协变量偏移 (Internal Covariate Shift)?
首先,我们用一句话来定义它:在深度神经网络的训练过程中,因为前面网络层的参数在不断变化,导致后面网络层接收到的数据分布也在不断发生变化的现象。
这就像一个多级流水线工厂。如果第一道工序的工人(第一层网络)还在学习阶段,他生产的零件(数据)时好时坏、尺寸忽大忽小,那么第二道工序的工人(第二层网络)就非常难办。他刚学会怎么处理“大尺寸”的零件,结果下一批来的全是“小尺寸”的,他之前学到的经验就没用了,必须重新适应。
这个“零件尺寸”不断变化的麻烦,就是内部协变量偏移。
一个具体的例子:猫的品种分类器
假设我们要训练一个简单的神经网络,用来区分“暹罗猫”(特征是脸黑)和“布偶猫”(特征是脸白)。为了简化,我们只用一个特征输入:脸部的亮度值(0 代表纯黑,1 代表纯白)。
我们的网络结构如下:
输入层 -> 隐藏层1 -> 隐藏层2 -> 输出层 (判断是哪种猫)
我们重点关注 隐藏层2 的学习过程。
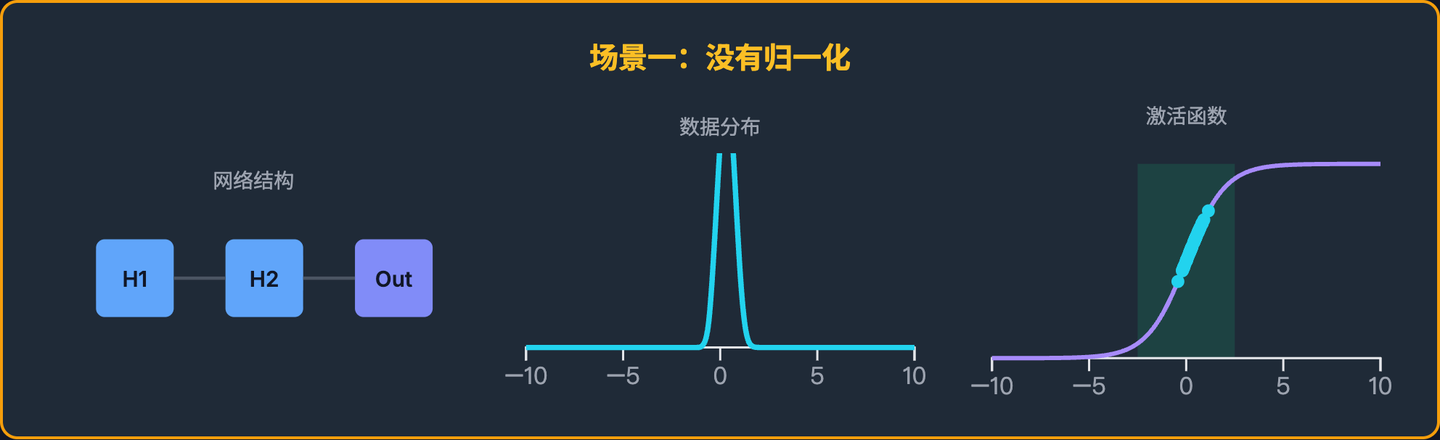
没有归一化的情况(问题发生)
训练初期(第 1 轮)
隐藏层1的参数(权重)是随机初始化的。它接收到“脸部亮度值”后,经过计算,输出给隐藏层2的可能是一批分布在[0.2, 0.4]之间的数据。隐藏层2开始学习:“哦,原来我收到的数据都在[0.2, 0.4]这个范围,我得根据这个范围来调整自己的参数,以便正确分类。”
训练中期(第 10 轮)
- 为了让最终的分类结果更准确,整个网络通过反向传播更新了参数。
隐藏层1的参数也发生了改变。 - 这次,
隐藏层1输出给隐藏层2的数据分布可能完全变了,比如,现在的数据都分布在[5.0, 8.0]这个范围内。 - 问题出现了!
隐藏层2一下子就懵了。它之前学到的所有“如何处理[0.2, 0.4]范围内数据”的经验,现在几乎完全作废。它面对的是一个全新的数据分布,必须从头开始学习如何处理[5.0, 8.0]的数据。
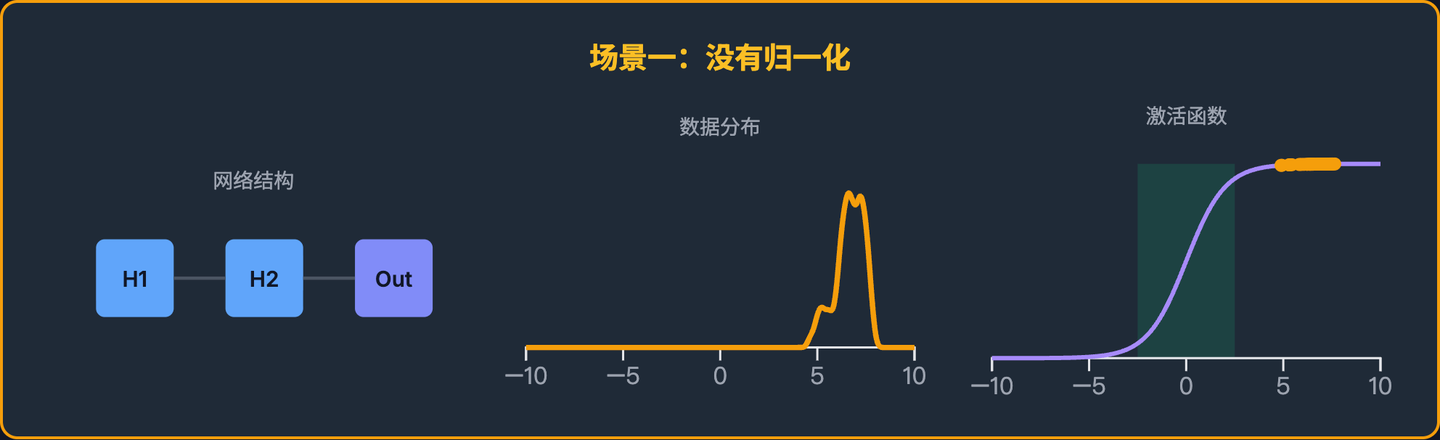
更严重的问题:梯度饱和
- 很多激活函数(比如 Sigmoid)在输入值很大或很小的时候,函数曲线会变得非常平坦。
- 当
隐藏层2收到像[5.0, 8.0]这样的大数值输入时,激活函数的输出可能全都挤在 1 附近,进入了“饱和区”。 - 在这个平坦的区域,梯度(导数)几乎为 0。这意味着
隐藏层2几乎无法再更新自己的参数,学习过程就此停滞。这就是梯度消失。
总结一下:隐藏层2 就像一个可怜的员工,上游部门 隐藏层1 给他的工作指令(数据分布)天天变,导致他无所适从,学习效率极低,甚至直接“躺平不干了”(梯度消失)。这就是内部协变量偏移的危害。
为什么归一化可以解决这个问题?
归一化的思想很简单:在每一层网络之间设置一个“数据标准化”的关卡,强行把数据拉回到一个稳定、标准的分布上。
我们在 隐藏层1 和 隐藏层2 之间插入一个归一化层(比如批量归一化 Batch Normalization)。
隐藏层1 -> **归一化层** -> 隐藏层2
现在我们再看看 隐藏层2 的工作体验:
训练初期(第 1 轮)
隐藏层1输出了一批数据,分布在[0.2, 0.4]。归一化层介入,它计算这批数据的均值和方差,然后进行一通操作,把这批数据强行转换成均值为 0、方差为 1 的标准分布。隐藏层2收到的是这批标准化的数据。
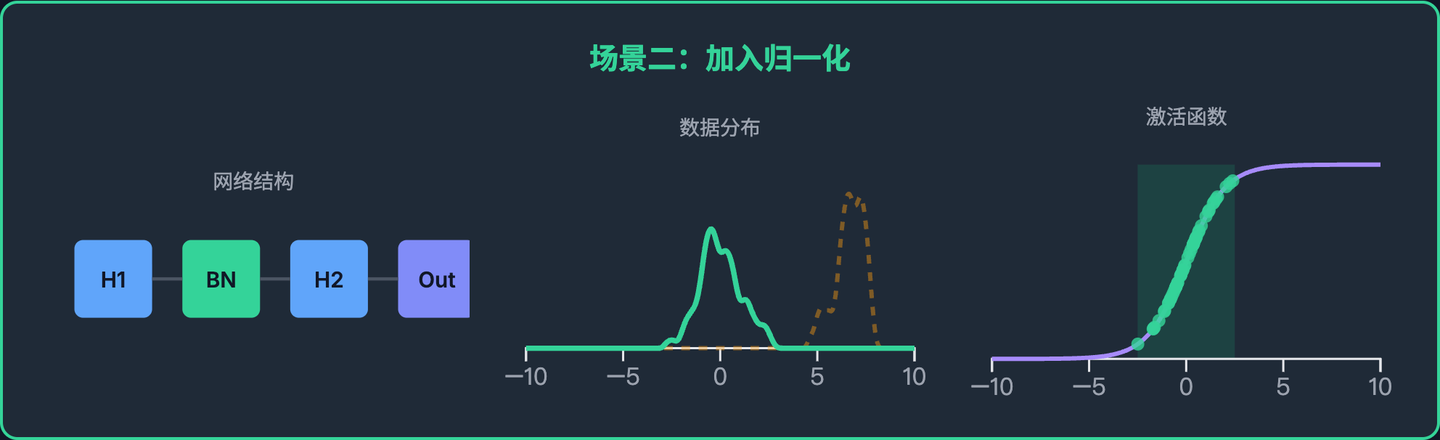
训练中期(第 10 轮)
隐藏层1的参数变了,输出了一批分布在[5.0, 8.0]的数据。归一化层再次介入,它才不管原始数据长什么样,它计算出这批新数据的均值和方差,然后又是一通操作,再次把这批数据强行转换成均值为 0、方差为 1 的标准分布。
这样带来的好处是:
- 控制激活值的尺度: 归一化把激活值控制在合理范围内(如 0 附近),避免了数值过大或过小。在使用 Sigmoid/Tanh 等激活函数时,这能让激活值远离饱和区,保证梯度的正常回传。
- 让训练过程更加“平稳”: 更重要的是,现代研究表明,归一化的主要作用是让梯度的变化更加可预测、温和。打个比方:训练神经网络就像在山路上找最高点。没有归一化时,山路崎岖不平,到处是陡坡和悬崖,你必须小心翼翼地挪步;有了归一化后,山路变得相对平缓,坡度变化温和,你可以放心地迈大步前进。从技术上说,就是归一化让损失函数变得更“平滑”(Lipschitz 常数更小),梯度不会突然剧烈变化,优化过程因此更加稳定。
- 允许更大的学习率: 因为“山路”变平缓了,梯度变化可预测了,我们可以放心地使用更大的学习率(迈更大的步子)来训练模型,大大加速训练过程。
虽然 Batch Normalization 最初是为了解决“内部协变量偏移”而提出的,但大量后续研究发现,BN 的实际收益机制更复杂。它并不是真正让每层输入分布“恒定不变”(事实上训练时用小批次统计量、推理时用滑动平均,分布本来就不一样),而是通过改善优化动力学来加速训练。
简单来说:归一化就像给神经网络装了一个“稳压器”,让训练过程更加平稳可控。
归一化技术的进化史
第一代解决方案:BatchNorm(批量归一化)
BatchNorm 的设计灵感来自于传统机器学习中的特征标准化。在传统机器学习中,我们通常会对输入特征进行标准化(减均值、除标准差),使不同量纲的特征具有可比性。BatchNorm 将这一思想延伸到深度网络的每一层——既然输入层需要标准化,那么每一层的输出(也是下一层的输入)同样需要标准化。
BatchNorm 在一个小批量(mini-batch)的数据中,对每一个特征进行归一化。它计算一个批次内所有样本在同一特征维度上的均值和方差,然后用这两个值来归一化该特征。
假设有 3 个学生(A,B,C)刚考完试,3 门科目的原始成绩如下:
| 学生 | 语文 | 数学 | 英语 |
|---|---|---|---|
| A | 70 | 140 | 80 |
| B | 80 | 60 | 90 |
| C | 90 | 70 | 100 |
问题来了:如果我们要评选“综合成绩最好的学生”,能直接把三科分数相加吗?
- 学生 A 总分:70 + 140 + 80 = 290
- 学生 B 总分:80 + 60 + 90 = 230
- 学生 C 总分:90 + 70 + 100 = 260
看起来 A 最高?但其实是不公平的,因为:
- 数学满分 150,语文和英语满分都是 100
- A 的数学 140 分看起来很高,但其实只是 93.3% 的得分率
- A 的语文 70 分看起来一般,但可能已经是 70% 的得分率
也就是说:不同科目的分数量纲不同,不能直接比较和相加。
BatchNorm 的解决方案:以每门科目为基准,看每个学生在该科目上相对于全班的表现。这就像是问:“在数学这门课上,A 的 140 分在全班中处于什么水平?是高于平均还是低于平均?偏离平均有多远?”
以每门科目为基准,计算全班统计量:
| 科目 | 均值 | 标准差 |
|---|---|---|
| 语文 | (70+80+90)/3 = 80.000 | √[((70-80)²+(80-80)²+(90-80)²)/3] = 8.165 |
| 数学 | (140+60+70)/3 = 90.000 | √[((140-90)²+(60-90)²+(70-90)²)/3] = 35.590 |
| 英语 | (80+90+100)/3 = 90.000 | √[((80-90)²+(90-90)²+(100-90)²)/3] = 8.165 |
归一化后的结果:
| 学生 | 语文 | 数学 | 英语 |
|---|---|---|---|
| A | (70-80)/8.165 = -1.225 | (140-90)/35.590 = 1.405 | (80-90)/8.165 = -1.225 |
| B | (80-80)/8.165 = 0.000 | (60-90)/35.590 = -0.843 | (90-90)/8.165 = 0.000 |
| C | (90-80)/8.165 = 1.225 | (70-90)/35.590 = -0.562 | (100-90)/8.165 = 1.225 |
现在可以回答问题了:谁的综合表现最好?
计算归一化后的总分(标准分之和):
- 学生 A:-1.225 + 1.405 + (-1.225) = -1.045
- 学生 B:0.000 + (-0.843) + 0.000 = -0.843
- 学生 C:1.225 + (-0.562) + 1.225 = 1.888
从上面的计算结果,我们可以得出一个结论:学生 C 综合表现最好。虽然 C 的原始总分(260)低于 A(290),但在消除了科目量纲差异后,C 在每门课上都相对稳定地高于平均水平,而 A 的高总分主要来自满分更高的数学科目。
总结一下:BatchNorm 是纵向看的,每次只关心一列(一个特征),用整个批次来标准化这一列。
BatchNorm 的局限性
首先,强依赖批次大小:批次太小时,统计量噪声大,损害性能
假设我们用 BatchNorm 训练一个图像分类模型。当 batch size = 32 时,每个特征的均值和方差是基于 32 张图片计算的,统计量相对稳定。但如果由于 GPU 显存限制,batch size 只能设为 2,那么:
- 第一个 batch:两张猫的图片 → 均值偏向“猫特征”
- 第二个 batch:两张狗的图片 → 均值偏向“狗特征”
- 第三个 batch:一张猫、一张狗 → 均值介于两者之间
这样每个 batch 的统计量波动剧烈,归一化后的值不稳定,模型难以收敛。这就像只用 2 个学生的成绩来计算“全班平均分”,代表性太差。
其次,不适用于 RNN:序列长度不一致,难以跨时间步归一化
在机器翻译任务中,不同句子长度不同:
- 句子 A:“I love you”(3 个词,3 个时间步)
- 句子 B:“The quick brown fox jumps”(5 个词,5 个时间步)
- 句子 C:“Hello”(1 个词,1 个时间步)
BatchNorm 需要在“同一特征维度”上跨样本计算统计量,但 RNN 的问题是:
- 时间步 3:只有句子 A 和 B 有数据,句子 C 已经结束了
- 时间步 5:只有句子 B 有数据
无法对齐不同长度的序列来计算批次统计量。这就像三个学生考试科目数量不同(A 考 3 门、B 考 5 门、C 考 1 门),无法按“第 4 门课”来计算全班平均分。
最后一个问题:训练与推理不一致:推理时需要使用训练时的移动平均统计量
训练时,我们用整个 batch(比如 32 张图片)计算均值和方差。但推理时往往只有 1 张图片:
- 训练时:batch = [图片 1,图片 2,…,图片 32] → 计算这 32 张图片的均值μ_batch 和方差σ²_batch
- 推理时:只有 1 张新图片 → 无法计算“批次统计量”
解决方案是:训练过程中维护一个移动平均(running mean/variance),推理时使用这个“训练时见过的全局统计量”。但这带来问题:
- 如果测试数据分布和训练数据不同(比如训练时都是白天图片,测试时来了夜晚图片),使用训练时的统计量会导致归一化不准确
- 训练和推理的计算路径不一致,增加了调试难度
这就像考试时用“全班历史平均分”来评估一个新转学生的成绩,但如果这个新生来自教学水平完全不同的学校,这个参考值就不准确了。
BatchNorm 的公式
\text{BatchNorm}(x) = \frac{x - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}} \cdot \gamma + \beta
其中 μ_B 是批次均值,σ²_B 是批次方差,ε 是一个很小的常数(如 10^{-5}),防止除零,γ 和 β 是可学习的参数,用于缩放和平移。
第二代解决方案:LayerNorm(层归一化)
LayerNorm 的提出源于对 BatchNorm 局限性的反思。研究者发现,在 RNN 和 Transformer 等序列模型中,每个样本的序列长度可能不同,且模型需要在单个样本上独立推理。这促使他们思考:归一化是否一定要依赖批次?能否让每个样本自己“标准化”自己? 答案是可以的:一个样本内部的不同特征维度(如 Transformer 中不同位置的 hidden states)同样存在分布差异。通过在样本内部的特征维度上计算统计量,LayerNorm 实现了完全独立于批次的归一化,这种“自给自足”的设计完美契合了序列模型的需求。
LayerNorm 完全在单个样本内部进行归一化,计算一个样本所有特征的均值和方差,然后用这两个值来归一化这个样本自己。
我们继续用学生的例子来理解 LayerNorm。现在换一个问题:我们不关心学生之间的比较,而是想帮助每个学生发现自己的强项和弱项。
LayerNorm 的解决方案:不管别的同学考得怎么样,只看每个学生自己,分析他各科成绩相对于个人平均水平的偏离程度。
这就像是问:“对于学生 A 来说,他的数学成绩相对于他自己的平均水平,是高还是低?偏离多少?”
对每个学生计算个人统计量:
| 学生 | 个人均值 | 个人标准差 |
|---|---|---|
| A | (70+140+80)/3 = 96.667 | √[((70-96.667)²+(140-96.667)²+(80-96.667)²)/3] = 30.551 |
| B | (80+60+90)/3 = 76.667 | √[((80-76.667)²+(60-76.667)²+(90-76.667)²)/3] = 12.472 |
| C | (90+70+100)/3 = 86.667 | √[((90-86.667)²+(70-86.667)²+(100-86.667)²)/3] = 12.472 |
归一化结果:
| 学生 | 语文 | 数学 | 英语 |
|---|---|---|---|
| A | (70-96.667)/30.551 = -0.873 | (140-96.667)/30.551 = 1.418 | (80-96.667)/30.551 = -0.545 |
| B | (80-76.667)/12.472 = 0.267 | (60-76.667)/12.472 = -1.336 | (90-76.667)/12.472 = 1.069 |
| C | (90-86.667)/12.472 = 0.267 | (70-86.667)/12.472 = -1.336 | (100-86.667)/12.472 = 1.069 |
现在可以回答问题了:每个学生的偏科情况如何?
学生 A 的分析:
- 个人平均分:96.667
- 语文 70 分 → 标准化后 -0.873(低于个人平均 0.873 个标准差)
- 数学 140 分 → 标准化后 1.418(高于个人平均 1.418 个标准差)
- 英语 80 分 → 标准化后 -0.545(低于个人平均 0.545 个标准差)
- 结论:严重偏科!数学是绝对强项,语文和英语都是弱项,尤其语文最弱
学生 B 的分析:
- 个人平均分:76.667
- 语文 80 分 → 标准化后 0.267(略高于个人平均)
- 数学 60 分 → 标准化后 -1.336(明显低于个人平均)
- 英语 90 分 → 标准化后 1.069(明显高于个人平均)
- 结论:有偏科倾向。英语是强项,数学是明显弱项
学生 C 的分析:
- 个人平均分:86.667
- 语文 90 分 → 标准化后 0.267(略高于个人平均)
- 数学 70 分 → 标准化后 -1.336(明显低于个人平均)
- 英语 100 分 → 标准化后 1.069(明显高于个人平均)
- 结论:和 B 类似的偏科模式。英语强、数学弱
总结一下:LayerNorm 是横向看的,每次只关心一行(一个样本),用这一行自己的所有数据进行标准化,不同样本之间互不影响。
LayerNorm 解决的问题
首先摆脱对批次大小的依赖:归一化完全在单个样本内完成。在训练 Transformer 模型时,假设我们的 GPU 显存只能支持 batch_size=1(单样本训练)。如果使用 BatchNorm,每次只基于 1 个样本计算统计量,均值和方差会极不稳定,导致模型无法收敛。但使用 LayerNorm,即使 batch_size=1,我们仍然可以在这个样本的 512 个 hidden dimensions 上计算均值和方差(统计量基于 512 个数值),归一化依然稳定可靠。这就像即使班上只有 1 个学生,我们仍然可以分析他自己 3 门课的成绩分布。
其次完美适用于序列模型:可以对每个序列独立推理。在机器翻译任务中,我们需要翻译三个句子:
- 句子 A: “Hello”(1 个词,hidden_dim=768)
- 句子 B: “I love AI”(3 个词,hidden_dim=768)
- 句子 C: “Deep learning is amazing”(4 个词,hidden_dim=768)
使用 LayerNorm 时,每个句子在每个时间步都基于自己的 768 维 hidden state 计算均值和方差,完全独立。句子 A 在 t=1 时刻归一化,句子 B 在 t=1,2,3 时刻分别归一化,互不干扰。这使得我们可以对任意长度的句子进行推理,而 BatchNorm 无法处理这种长度不一致的情况。
最后 LayerNorm 能保证训练与推理一致性:无需使用训练时的统计量,推理结果稳定。假设我们训练了一个文本分类模型,训练数据都是新闻文章(平均长度 200 词)。推理时来了一条短消息 “Great!”(只有 1 个词)。如果使用 BatchNorm,推理时必须使用训练阶段记录的 running mean/variance(基于 200 词长度的统计量),这对 1 个词的短文本并不适用,可能导致归一化不准确。但使用 LayerNorm,无论训练还是推理,都是基于当前样本自己的 hidden dimensions 计算统计量。训练时基于 200 个 token 的 768 维,推理时基于 1 个 token 的 768 维,计算方式完全一致,不需要维护任何历史统计量。
LayerNorm 的公式
\text{LayerNorm}(x) = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} \cdot \gamma + \beta
其中 μ 是均值,σ² 是方差,ε 是一个很小的常数(如 10^{-5}),防止除零,γ 和 β 是可学习的参数,用于缩放和平移。
第三代优化:RMSNorm(均方根归一化)
RMSNorm 的提出是基于对 LayerNorm 的深入研究。研究者在分析 LayerNorm 时发现,归一化操作包含两个步骤:中心化(re-centering)和缩放(re-scaling)。他们提出疑问:这两个步骤都是必需的吗?通过大量实验,他们发现中心化步骤(减去均值)对模型性能的贡献微乎其微,真正起作用的是缩放操作:控制激活值的幅度。
同样是学生成绩的例子,如果我们只是想知道“这组成绩数值的整体规模有多大”,是否一定要计算平均分?
我们知道:
- 学生 A:语文 70、数学 140、英语 80(数值整体偏大)
- 学生 B:语文 80、数学 60、英语 90(数值整体偏小)
如果我们只关心“把各科分数缩放到统一的数值范围”,而不关心“每科相对于个人平均的偏离”,那么减去均值这一步可能是多余的。
RMSNorm 的解决方案:也是只看每个学生自己,但不关心平均分,只看这组成绩数值的“整体规模”(均方根),然后用这个规模值把所有成绩缩放到相似的数值范围。
这就像是问:“学生 A 的成绩数值整体 ’ 量级 ’ 有多大?我们用这个量级来把各科成绩缩放到可比较的范围。”
为什么需要缩放到统一范围?
在学生例子中:
- 语文满分 100,数学满分 150,英语满分 100
- 不同科目的分数量纲不同,无法直接比较
- RMSNorm 通过除以 RMS,把它们缩放到统一的数值范围(如 0.6-1.4 之间)
- 这样缩放后,不同量纲的分数就可以在同一尺度下比较了
在神经网络中:
- 一个样本的 4096 维 hidden state,虽然量纲相同(都是浮点数)
- 但这 4096 个数值的绝对大小(magnitude)可能差异很大(有的是 0.01,有的是 100)
- RMSNorm 通过除以 RMS,把它们缩放到相似的数值范围(如 0.5-2.0 之间)
- 这样可以防止某些维度的数值过大或过小,稳定梯度传播
无论是学生例子中的“统一量纲”,还是神经网络中的“统一数值范围”,RMSNorm 的数学操作都是一样的:通过除以 RMS,把所有数值缩放到可比较的尺度。
计算每个学生的均方根(RMS):
| 学生 | RMS |
|---|---|
| A | √[(70²+140²+80²)/3] = 104.881 |
| B | √[(80²+60²+90²)/3] = 78.740 |
| C | √[(90²+70²+100²)/3] = 86.667 |
归一化结果:
| 学生 | 语文 | 数学 | 英语 |
|---|---|---|---|
| A | 70/104.881 = 0.667 | 140/104.881 = 1.335 | 80/104.881 = 0.763 |
| B | 80/78.740 = 1.016 | 60/78.740 = 0.762 | 90/78.740 = 1.143 |
| C | 90/86.667 = 1.019 | 70/86.667 = 0.808 | 100/86.667 = 1.154 |
根据 RMSNorm 的结果,我们也可以分析学生的成绩
学生 A 的分析:
- RMS(均方根)= 104.881,这是三人中最高的,说明 A 的成绩数值整体量级最大
- 归一化后:语文 0.667、数学 1.335、英语 0.763
- A 的成绩被一个较大的 RMS 值缩放,数学(1.335)在归一化后仍然突出,语文(0.667)相对较弱
学生 B 的分析:
- RMS = 78.740,这是三人中最低的,说明 B 的成绩数值整体量级最小
- 归一化后:语文 1.016、数学 0.762、英语 1.143
- B 的成绩“能量”最小,但归一化后各科都在 0.76-1.14 之间,分布相对均衡
学生 C 的分析:
- RMS = 86.667,介于 A 和 B 之间
- 归一化后:语文 1.019、数学 0.808、英语 1.154
- C 的成绩“能量”中等,归一化后各科也在 0.81-1.15 之间,分布均衡
对比 LayerNorm 和 RMSNorm 的结果:
| 学生 | LayerNorm 语文 | RMSNorm 语文 | LayerNorm 数学 | RMSNorm 数学 | LayerNorm 英语 | RMSNorm 英语 |
|---|---|---|---|---|---|---|
| A | -0.873 | 0.667 | 1.418 | 1.335 | -0.545 | 0.763 |
- LayerNorm 的结果有正有负(因为减去了均值),强调相对于个人平均的偏离
- RMSNorm 的结果都是正数,只关心把数值缩放到统一范围
- 两者适用场景不同:LayerNorm 更适合需要识别偏差的场景,RMSNorm 更适合只需要统一尺度的场景
总结一下,RMSNorm 也是横向看的,和 LayerNorm 一样对单个样本内部标准化,但省去了减均值这步,只保留缩放。
RMSNorm 解决的问题
首先它解决了计算成本过高的问题:通过省略不必要的中心化步骤,减少计算开销。假设我们在训练一个大型语言模型(如 GPT),每层都需要对隐藏状态进行归一化。以一个维度为 4096 的隐藏向量为例(忽略 GPU 的计算优化,仅从逻辑上推导):
LayerNorm 的计算步骤:
- 第一步:计算均值 μ = (x₁ + x₂ +… + x₄₀₉₆) / 4096(需要 4096 次加法和 1 次除法)
- 第二步:计算每个元素与均值的差 (xᵢ - μ)(需要 4096 次减法)
- 第三步:计算方差 σ² = Σ(xᵢ - μ)² / 4096(需要 4096 次平方、4096 次加法、1 次除法)
- 第四步:归一化 (xᵢ - μ) / √(σ² + ε)(需要 4096 次除法)
- 总计:约 16,000 次运算
RMSNorm 的计算步骤:
- 第一步:计算平方和 Σxᵢ²(需要 4096 次平方和 4096 次加法)
- 第二步:计算 RMS = √(Σxᵢ² / 4096)(需要 1 次除法和 1 次开方)
- 第三步:归一化 xᵢ / RMS(需要 4096 次除法)
- 总计:约 12,000 次运算,减少了 25% 的计算量
其次,RMSNorm 算法对硬件友好:更简单的操作在 GPU 上执行更高效。现代 GPU 的计算特点是“吞吐量高但延迟敏感”,特别不喜欢“依赖链”(前一步的结果必须完成才能开始下一步)。LayerNorm 需要执行“减均值 → 计算方差 → 归一化”三步操作,而 RMSNorm 直接“平方求和 → 归一化”,同步点更少,内核更易融合。
RMSNorm 的公式
\text{RMSNorm}(x) = \frac{x}{\sqrt{\frac{1}{n}\sum_{i=1}^{n}x_i^2 + \epsilon}} \cdot \gamma
ε 是一个很小的常数(如 10^{-5}),防止除零,γ 是可学习的参数,用于缩放和平移。
RMSNorm 源码分析
RMSNorm 类主要包含三个核心方法:
__init__: 初始化模块。rms_forward: 执行标准的 RMSNorm。add_rms_forward: 先将输入与一个残差(residual)相加,然后再执行 RMSNorm。
__init__(初始化方法)
def __init__(
self,
hidden_size: int,
eps: float = 1e-6,
) -> None:
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(hidden_size))hidden_size: 这是输入张量最后一个维度的尺寸,通常是模型的隐藏层维度(或嵌入维度)。eps(epsilon): 一个非常小的数值(默认为1e-6),用于防止在计算平方根倒数时出现除以零的错误,保证数值稳定性。self.weight: 这是一个可学习的参数(nn.Parameter)。它的作用是在归一化之后对结果进行缩放,让模型可以自适应地调整每个特征的尺度。它被初始化为全 1,这样在训练开始时,它对归一化结果没有影响。self.weight就是上面 RMS 公式中的 γ 参数。
rms_forward(标准 RMSNorm)
这个方法实现了 RMSNorm 的核心计算逻辑。其数学公式为:
\text{output} = \frac{x}{\sqrt{\frac{1}{n}\sum_{i=1}^{n} x_i^2 + \epsilon}} \cdot w
其中,x = (x\_1,…, x\_n) 是输入向量,w 是可学习的 weight 参数。
@torch.compile
def rms_forward(
self,
x: torch.Tensor,
) -> torch.Tensor:
orig_dtype = x.dtype
# 1. 为了计算精度,先将输入转换为 float32
x = x.float()
# 2. 计算均方值 (Mean Square)
# x.pow(2) -> 计算每个元素的平方
# .mean(dim=-1, keepdim=True) -> 沿着最后一个维度计算均值
var = x.pow(2).mean(dim=-1, keepdim=True)
# 3. 计算均方根的倒数 (Reciprocal Square Root)
# var + self.eps -> 加上 epsilon 防止除零
# torch.rsqrt -> 计算平方根的倒数,即 1/sqrt(z)
inv_std = torch.rsqrt(var + self.eps)
# 4. 归一化并应用可学习的权重
# x.mul_(inv_std) -> 将输入 x 乘以 inv_std,完成归一化
# .to(orig_dtype) -> 转换回原始数据类型(如 float16)
# .mul_(self.weight) -> 乘以可学习的缩放参数 weight
x = x.mul(inv_std).to(orig_dtype).mul(self.weight)
return xadd_rms_forward(融合残差连接的 RMSNorm)
在 Transformer 的架构中,一个常见的模式是 “Add & Norm”:先将残差连接(residual connection)加到输入上,然后再进行归一化。这个方法就是为了高效地执行这个融合操作。
@torch.compile
def add_rms_forward(
self,
x: torch.Tensor,
residual: torch.Tensor,
) -> tuple[torch.Tensor, torch.Tensor]:
orig_dtype = x.dtype
# 1. 先将输入 x 和残差 residual 相加
x = x.float().add_(residual.float())
# 2. 将相加后的结果保存为新的残差,供下一层使用
residual = x.to(orig_dtype)
# 3. 后续步骤与 rms_forward 完全相同
var = x.pow(2).mean(dim=-1, keepdim=True)
inv_std = torch.rsqrt(var + self.eps)
x = x.mul(inv_std).to(orig_dtype).mul(self.weight)
# 4. 返回归一化后的结果和更新后的残差
return x, residual这种 “pre-normalization” 的结构(先 Add 再 Norm)被证明在深度模型中能提供更好的训练稳定性。该方法返回更新后的 residual,是因为这个值将作为下一层(例如 FFN 层)的输入,并再次用于其输出的残差连接。
forward(前向传播主函数)
这个方法是模块的入口。它通过判断 residual 参数是否为 None 来决定调用哪个具体的实现。
def forward(
self,
x: torch.Tensor,
residual: torch.Tensor | None = None,
) -> torch.Tensor | tuple[torch.Tensor, torch.Tensor]:
if residual is None:
# 如果没有提供残差,就执行标准的 RMSNorm
return self.rms_forward(x)
else:
# 如果提供了残差,就执行 "Add & Norm"
return self.add_rms_forward(x, residual)这种设计提供了很好的灵活性,让同一个模块既可以用于标准的归一化场景,也可以用于融合了残差连接的场景。
总结
在这篇文章中,我们完成了对 RMSNorm 归一化技术的全面解析。让我们回顾一下核心要点:
归一化的本质:我们从内部协变量偏移问题出发,理解了归一化技术提出的历史动机。虽然最初的目标是解决数据分布不断变化的问题,但最近的研究发现,归一化的真正价值在于:通过控制激活与梯度的尺度,平滑优化过程,使训练过程更加稳定可控。它就像是在每一层网络之间设置的“稳压器”,不是真的让分布“恒定不变”,而是让优化过程变得更加平滑和可预测。
技术演进路径:
- BatchNorm:纵向归一化,在批次维度上计算统计量。虽然有效,但强依赖批次大小,不适用于序列模型,且训练推理不一致。
- LayerNorm:横向归一化,在特征维度上计算统计量。完美解决了 BatchNorm 的三大问题,成为 Transformer 的标配。
- RMSNorm:LayerNorm 的简化版,省去了中心化步骤(减均值),只保留缩放操作。在保持效果的同时,将计算量减少约 25%,且对硬件更友好。
工程实现:通过 nano-vllm 的源码分析,我们看到了 RMSNorm 的两种实现模式:
rms_forward:标准的 RMSNorm 计算add_rms_forward:融合了残差连接的优化版本
RMSNorm 的成功告诉我们一个重要的工程哲学:简化不等于妥协。通过深入分析问题本质(归一化的核心是缩放而非中心化),我们可以在几乎不损失效果的前提下,大幅提升计算效率。这种“做减法”的智慧,在大模型时代尤为重要。