前言
最近 AI 领域有个挺火的方向,就是让 AI 像人一样去操作图形界面(GUI),比如自动帮你订外卖、处理邮件等等。智谱 AI 推出的 AutoGLM 就是这个方向的一个尝试(产品地址:https://autoglm-research.zhipuai.cn/,开源地址:https://xiao9905.github.io/AutoGLM/)。
大家可能会觉得,大模型这么聪明,让它点点鼠标、填填表格应该不难吧?但实际情况远比想象的复杂。今天我们就来扒一扒 AutoGLM 背后的技术思路(主要参考这两篇论文:AutoGLM: Autonomous Foundation Agents for GUIs 和 WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning),看看让 AI 学会“点点点”到底难在哪,以及研究人员们想了哪些办法。
解决方案一:拆分任务,专攻定位
核心挑战:规划很强,定位很“方”
我们先来看看第一个大问题。研究人员发现,现在的大模型(LLM/LMM)在理解“要做什么”(规划)方面其实还行,比如你让它“搜索北京天气”,它大概知道要去搜索框输入文字然后点击搜索按钮。但问题出在“点哪里”(定位)上。
简单来说,模型知道要去点“搜索按钮”,但在屏幕上一堆花花绿绿的元素里,精确找到那个按钮的具体位置,对它来说是个老大难的问题。经常点错地方,任务自然就失败了。
既然定位是个瓶颈,那干脆把任务拆成两步:
- 规划 (Planning): 大模型先想好操作步骤,比如“找到搜索框”,“输入文字”,“点击搜索按钮”。
- 定位 (Locating): 针对每一步需要交互的元素(比如“搜索框”),专门训练一个模型来精确找到它在屏幕上的位置。

这个“定位”模型是怎么炼成的呢?
AutoGLM 的论文里面没说细节,但提到了一个类似的工作:《Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents》
这篇论文里提到了一个叫 UGround 的相关工作,专门解决这个问题。你可以把它想象成一个“指哪打哪”的模型。训练它需要喂给它三样东西:
- 输入 - GUI 屏幕截图: 就是我们看到的那个界面图片。
- 输入 - 指称表达 (Referring Expression): 用自然语言描述要找的那个元素,比如“那个红色的登录按钮”、“页面右上角的购物车图标”。
- 输出 - 像素坐标: 模型需要准确预测出这个元素在图片上的中心点坐标,比如
(1344, 1344),这样才能实现精确点击。
训练数据从哪来?
要让模型学会定位,需要海量的(屏幕截图, 指称表达, 坐标)数据。研究人员也是下了血本:
- 主力军 (Web-Hybrid): 这是他们自己搞的主要数据集,基于网页自动生成的。他们先抓取大量网页,然后用规则和 LLM 生成各种五花八门的“指称表达”(比如描述颜色、位置、功能的),覆盖了 900 万个元素!
- 补充兵 (Web-Direct): 也是基于网页,但直接用更强的 GPT-4o 生成描述,追求更自然的表达方式。
- 外援 (Android Datasets): 把现有的各种 Android 应用界面数据集也整合进来,增加多样性。
核心思想就是: 用尽可能多、尽可能接近人类表达习惯的数据,教会模型看懂截图和描述,然后准确地输出坐标。
解决方案二:在实践中进化 —— 强化学习与课程学习
光会定位还不够,要完成复杂任务,AI Agent 需要在真实环境中不断尝试和学习。这里就用到了强化学习(Reinforcement Learning, RL)的路子。
简单来说,就是让 Agent 在一个模拟的网页环境(比如 WebArena)里:
- 看一眼当前页面和任务指令。
- 决定下一步操作(点哪个元素,输入什么)。
- 环境执行操作,给它看新页面。
- 重复这个过程,直到任务完成或失败。
- 根据结果给 Agent 打分(奖励或惩罚),让它调整策略,下次做得更好。
但是,强化学习训练也有自己的坑:
- 训练任务稀缺: 哪有那么多现成的、标注好的网页任务给它练手?
- 反馈信号稀疏: 很多时候要操作好多步才能知道任务成败,中间步骤做对了还是做错了,很难及时得到反馈。
- 策略漂移: 模型一边学一边变,可能导致训练不稳定。
AutoGLM 的妙招:自进化课程学习
看到这里你可能有点晕了,这又是什么新概念?没关系,我们把它拆开看。 这个策略的核心思想是:让 AI 从易到难地学习,而且这个“难易程度”是动态调整的。
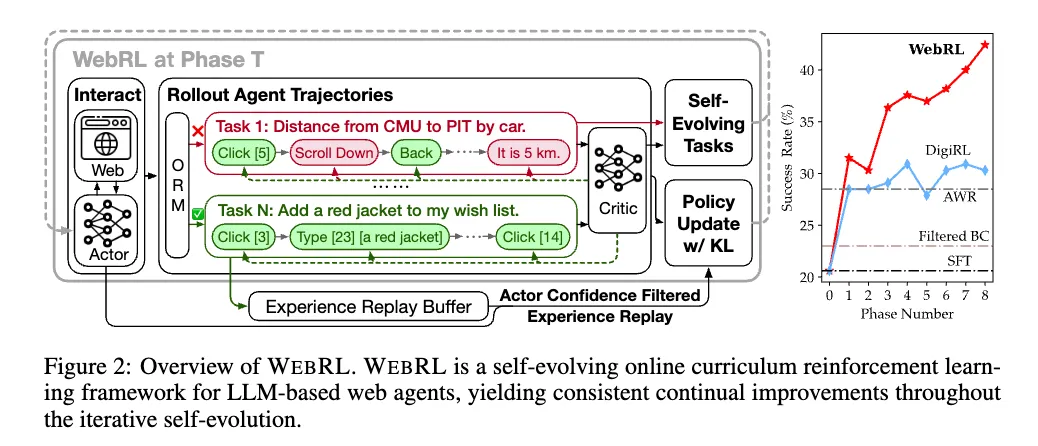
它主要包含两个步骤:
- 生成 (Generation): 从失败中创造新任务
- 系统会看 Agent 在哪些任务上失败了。失败说明这些任务有挑战性。
- 然后,利用 GPT-4o 这样的强力模型,基于这些失败的任务,生成一批相似但又略有不同的新任务指令。比如,上次让它搜“北京天气”失败了,这次就生成“查询上海今日气温”、“搜索广州未来三天预报”等变体。
- 目的: 针对性地让 Agent 在薄弱环节进行更多、更多样化的练习。
- 过滤 (Filtering): 控制难度,确保可行
- 生成的新任务不能一股脑全丢给 Agent,万一太难直接劝退了呢?
- 这里引入一个 “评论家” (Critic) 模型,专门评估每个新任务对当前 Agent 来说有多难。
- 只选择那些难度评分在合适范围(比如论文里提到的 0.05 到 0.75)的任务。太简单的(没挑战)和太难的(学不会)都不要。
- 同时,还要确保这些任务在模拟环境(WebArena)里是真的可以完成的,会有人工或 GPT-4o 再审一遍,排除掉那些不切实际的任务。
- 目的: 保证 Agent 总是在“跳一跳能够得着”的难度区间学习,效率最高。
难度逐步提升的例子:
看看 Figure 8 里的指令变化,就能直观感受到这个“课程”是怎么变难的:
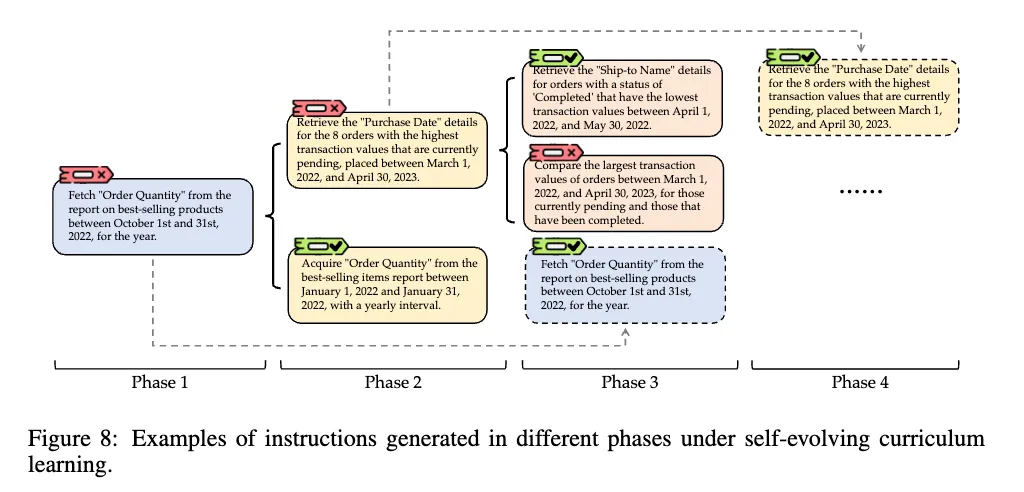
- Phase 1: 还比较简单,就是从报告里找个数字。
- Phase 2: 开始复杂了,要按条件筛选(待处理、最高交易额),再找特定信息(购买日期)。
- Phase 3: 条件更复杂(已完成、最低交易额)。
- Phase 4: 不仅要找,还要比较不同条件下的结果。
是不是很像我们上学时的感觉?先学加减,再学乘除,难度一点点加上去。
总结
让 AI 学会像人一样操作图形界面,挑战确实不小。AutoGLM 主要从两个方面入手:
- 拆解问题: 把复杂的交互任务拆分成“规划”和“定位”两步,用专门的模型解决“点哪里”这个瓶颈问题,并通过海量数据训练定位精度。
- 智能训练: 采用强化学习,并通过“自进化课程学习”策略,动态生成难度合适的任务,让 Agent 从易到难、循序渐进地提升能力,克服训练数据稀缺和反馈稀疏的问题。
虽然离真正完美的 GUI Agent 还有距离,但这些思路无疑为我们指明了方向。未来 AI 能不能真的帮你处理各种电脑、手机上的繁琐操作,这些技术是关键的一环。